Blog
A Comprehensive Guide to AI Evaluation and Red Teaming in Healthcare
In this post, Weiran Yao, Ph.D., outlines the actAVA framework for evaluating, red-teaming, and governing healthcare AI systems. This structured methodology underpins actAVA’s KORA|RED testing suite and ensures that AI applications are safe, compliant, effective, and trustworthy from development to deployment.
By Weiran Yao
The adoption of AI in healthcare promises to revolutionize patient care, streamline operations, and accelerate research. However, the stakes are uniquely high. An error in a consumer application might be an inconvenience; in healthcare, it can directly impact patient safety and clinical trust.
Our Chief AI Officer, Dr. Werian Yao, is an AI research leader with deep expertise in large-scale model training, reasoning engines, and multi-agent systems. He has a Ph.D. in Machine Learning from CMU and has published 85+ papers on AI. He holds a Ph.D. in Machine Learning from CMU and has published more than 85 papers on AI. He also holds 13 U.S. patents and serves as an area chair on the program committees for NeurIPS, ICML, ICLR
In this post, Weiran outlines the actAVA framework for evaluating, red-teaming, and governing healthcare AI systems. This structured methodology underpins actAVA’s KORA|RED testing suite and ensures that AI applications are safe, compliant, effective, and trustworthy from development to deployment.
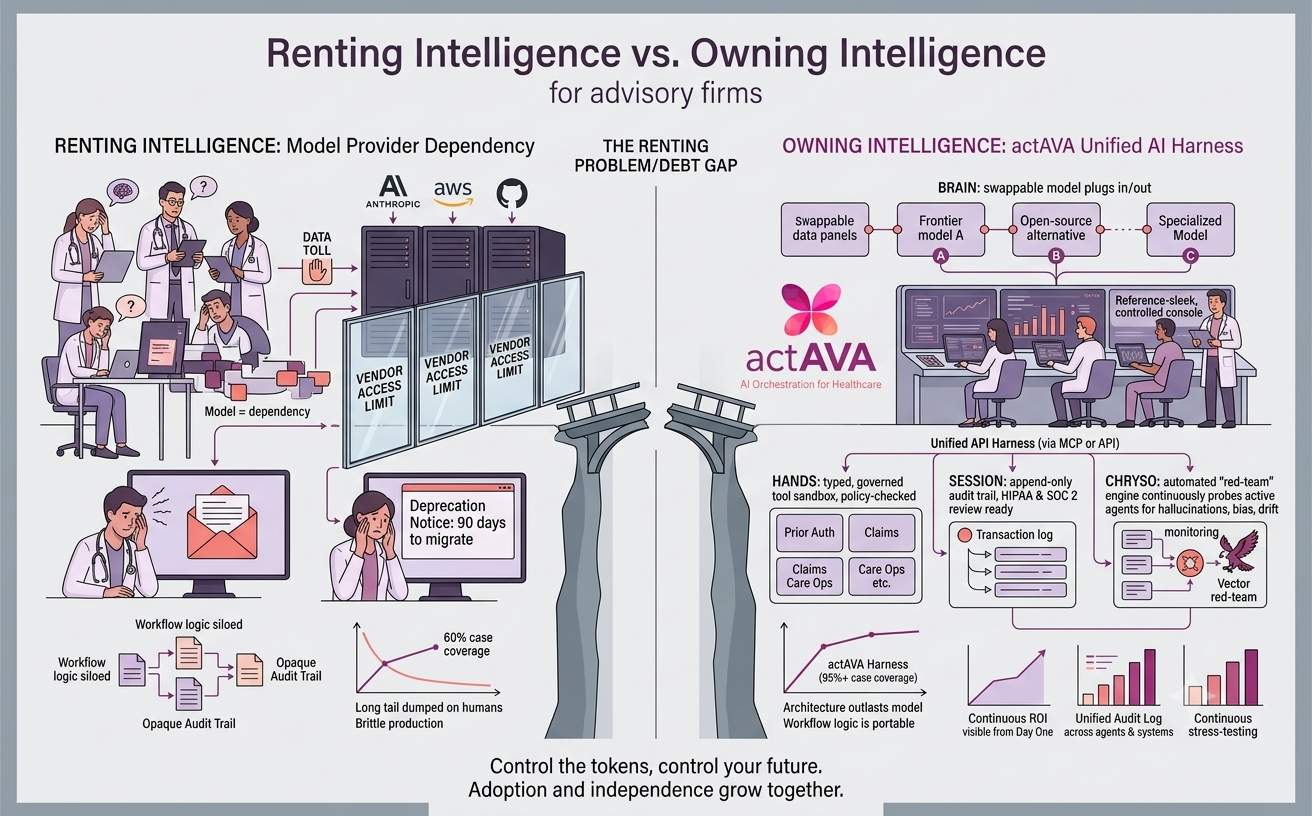
Our Approach
At actAVA, we believe that safety isn't a bottleneck to innovation—it is the prerequisite for it. We have developed a comprehensive framework for evaluating, red-teaming, and governing healthcare AI systems. Our approach is built on three core pillars:
Risk Mitigation: Proactively eliminating risks related to safety, HIPAA compliance, and hallucinations.
Operational Excellence: Automating testing within CI/CD pipelines to deploy faster.
Clinical Trust: Providing the evidence and transparency clinicians need to actually use these tools.
Here is how we turn that philosophy into a rigorous engineering reality.

Part 1: The Non-Negotiables (Universal Metrics)
Before any AI agent interacts with a patient or touches an EHR, it must pass a foundational set of universal checks. These are the "hard gates." If an agent fails here, it doesn't matter how smart or conversational it is—it cannot be deployed.

PHI/PII Leakage (Zero Tolerance): We test for the strict absence of Protected Health Information in outputs or logs. In healthcare, privacy isn't just a feature; it's the law. A single leak is a critical failure.
Hallucination & Faithfulness: Does the output invent medical facts? We measure faithfulness to ensure the AI's response is factually supported by the provided context, preventing the "invention" of diagnoses or guidelines.
Safety & Bias (Stratified): We don't just look for overall accuracy; we look for disparate impact. Does the model perform worse for specific demographic groups? We audit for intersectional bias to ensure equitable care.
Prompt Injection Robustness: Can the agent be "tricked" into bypassing its safety rules? We red-team agents against jailbreak attempts to ensure they remain within their intended scope.
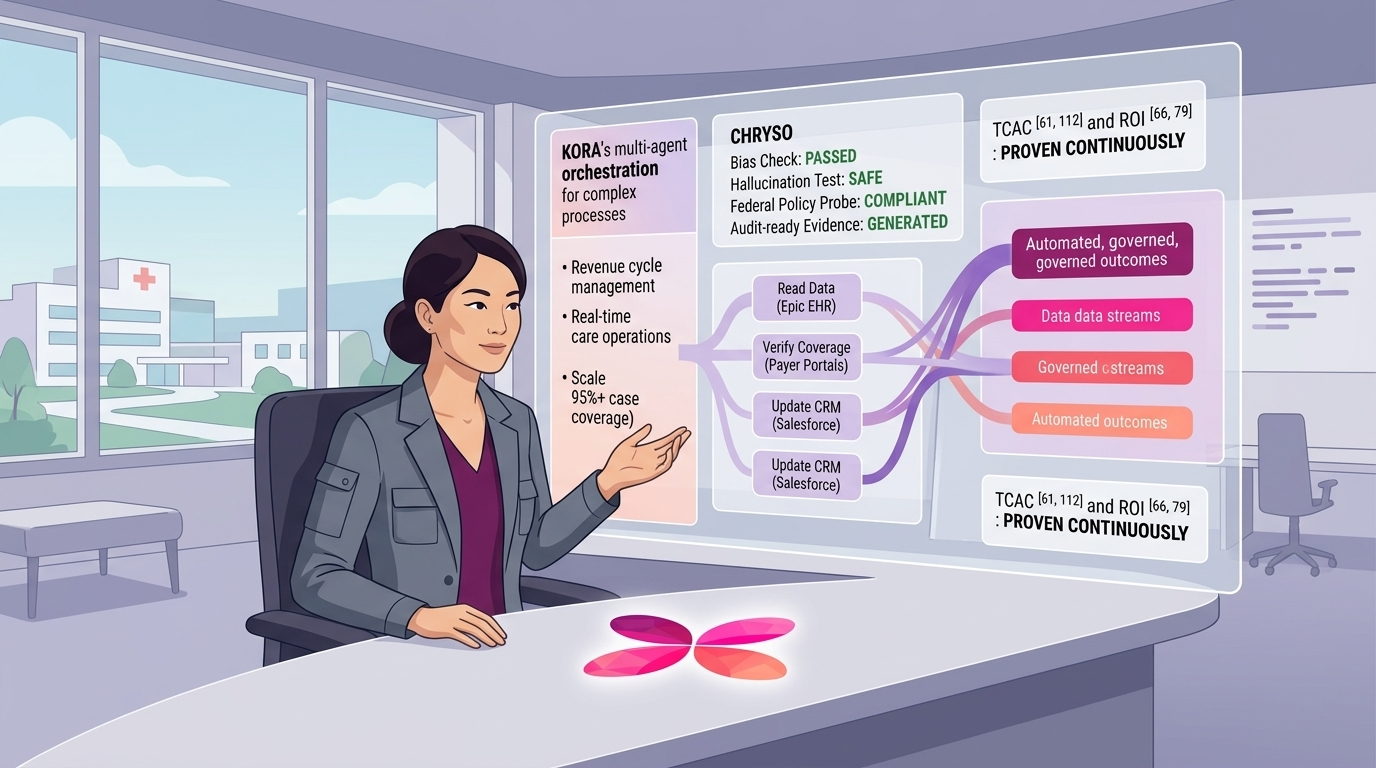
Part 2: Specialized Evaluation for Healthcare Workflows
Once baseline safety is established, we must recognize that a Symptom Checker has a very different risk profile from a Prior Authorization Bot. actAVA provides specialized metric suites tailored to the specific demands of each workflow.

1. RAG Agents (Clinical Decision Support): For agents that retrieve and synthesize information, we must evaluate both the retrieval (did we find the right data?) and the generation (did we explain it correctly?).
Context Recall: Did we retrieve all relevant documents? Missing a document containing a contraindication is a safety risk.
Citation Correctness: This is vital for clinical trust. Does the citation actually support the claim made?
Abstention: Does the agent know when to say, "I don't have enough information"? In medicine, admitting ignorance is safer than guessing.
2. Agentic Workflows (Billing, Scheduling, Prior Auth): For agents that execute tasks, we measure procedural correctness.
Task Completion: Did the agent successfully finish the end-to-end workflow?
Tool Correctness: Did it use the right API with the right arguments?
Minimum Necessary PHI: Does the agent only request / transmit the absolute minimum data required for the step?
This is a core HIPAA principle that generic AI often ignores.
3. Conversational Agents (Patient-Facing): Here, the user experience is the safety mechanism.
Triage Safety: Does the agent correctly identify red-flag symptoms and escalate to emergency services or a nurse line immediately?
Empathy & Tone: Is the language appropriate? Alarmist language can cause patient distress; dismissive language erodes trust.
Knowledge Retention: Does the agent remember an allergy mentioned three turns ago?
Part 3: From Manual Testing to Automated Governance
A list of metrics is only a starting point. To truly scale, evaluation must be embedded in your CI/CD pipeline. At actAVA, we treat evaluation as code. We implement automated quality gates to prevent regressions. Development teams can set hard thresholds. For example:
FAIL if PIILeakage is not 0.
FAIL if Faithfulness is < 0.80.
WARN if Bias subgroup performance gap is > 5%.
We also offer ready-to-use Preset Suites (e.g., Clinical Note Summarization Suite, AI Equity Audit Suite) so teams don't have to build these test harnesses from scratch.
Part 4: Future-Proofing with Scalable Oversight & Autonomous Red Teaming
The evaluation lifecycle doesn’t end at deployment. In fact, that's where the real learning begins. Scalable Oversight: within the platform, clinicians review and annotate intermediate AI artifacts (e.g., evidence sets, plans, medication reconciliation, clinical calculations) alongside final outputs, with AI evaluation to highlight uncertainties, missing evidence, and policy risks. Their corrections don’t just fix a single result: each edit is automatically converted into a versioned golden test case—so if a doctor revises a summary, that revision becomes a gating requirement the model must pass in the next update.
Looking ahead, we’re extending this loop into continuous, autonomous red teaming. The system will continuously probe production agents for new vulnerabilities—generating adversarial prompts to surface failures in dosage calculations, contraindication checks, or privacy filters—and then use generative AI to propose targeted remediations (prompt/tooling changes, guardrails, eval expansions, or model updates). Over time, oversight and red teaming work together as a self-improving safety flywheel: real clinician feedback expands the test suite, autonomous attacks search for new gaps, and every fix becomes durable, measurable, and continuously enforced.
Conclusion
In healthcare, "move fast and break things" is not an option. But "move slow and fear everything" is equally dangerous, as it denies patients access to life-saving technology. By implementing a rigorous, automated framework like actAVA, we can move fast and keep things safe.
Let’s build AI that doctors can trust and patients can rely on.

Written by
Weiran Yao
CAIO & Co-Founder