Release Notes
actAVA Platform Release Notes v5 (May 2026)
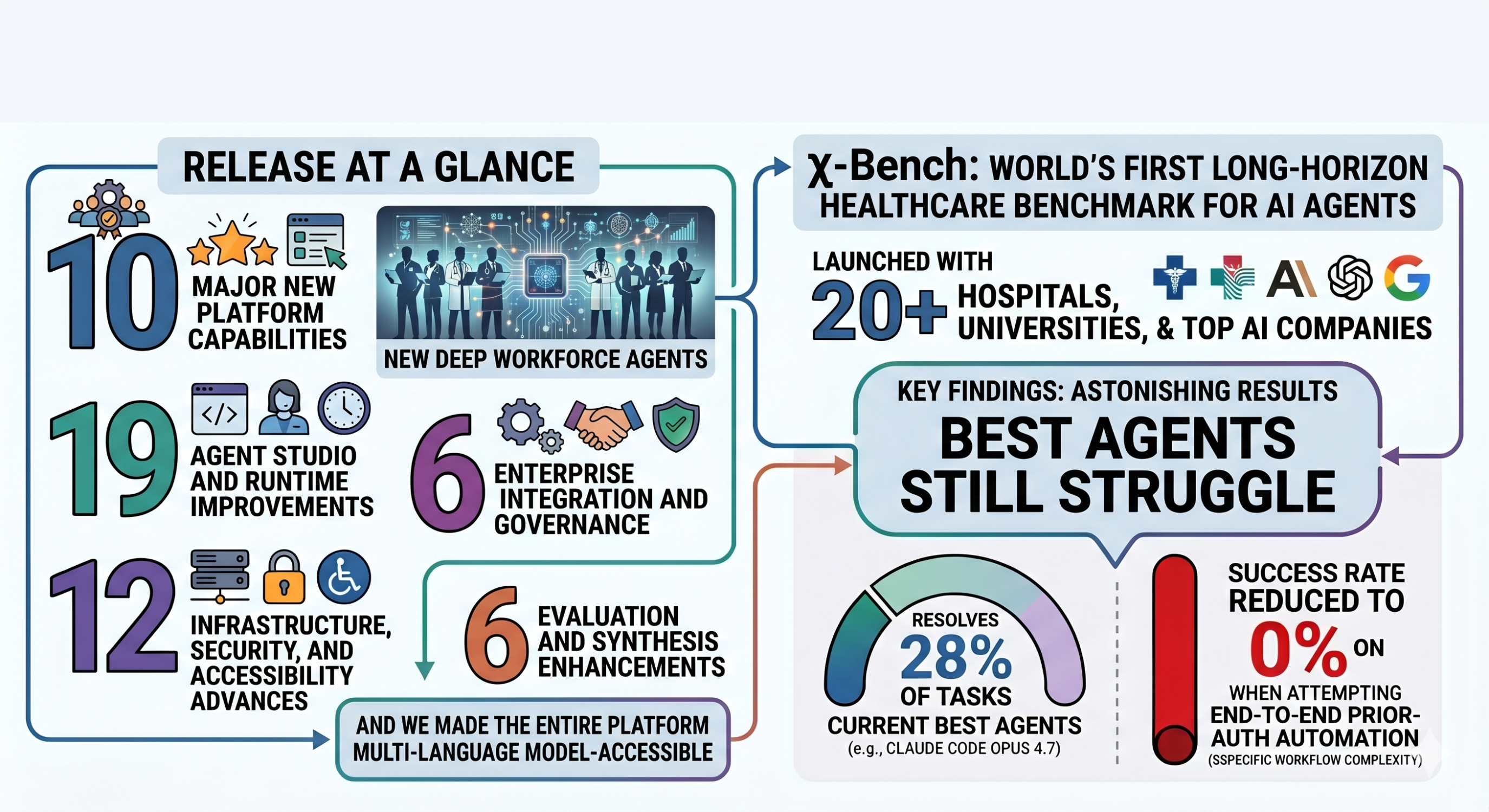
Release at a glance: 10 new deep Workforce Agents, 6 major new platform capabilities, 6 enterprise integration and governance upgrades, 19 Agent Studio and runtime improvements, 6 evaluation and synthesis enhancements, and 12 infrastructure, security, and accessibility advances. And we made the entire platform multi-language model-accessible. And we launched χ-Bench with 20+ hospitals, universities, and leaders from top AI companies. This is the world's first long-horizon healthcare benchmark for AI agents. The findings are astonishing: the best agent (e.g., Claude Code Opus 4.7) still struggles to automate healthcare workflows, such as end-to-end prior authorization. The best agent today resolves 28% of tasks; end-to-end prior-auth automation reduces the success rate to 0%.
By Deon Metelski
Key Feature Highlights
With the actAVA v5 release, we move from "agents that work" to "agents that scale across the enterprise." v5 doubles down on making actAVA the right choice for Enterprise Agentic Lifecycle Management.
We can now use multiple large language models (with Anthropic Opus 4.7 still the default) as the inference engine on a per-agent basis. We give our customers the ability to own their own agentic roadmap, at a cost/quality curve they choose for each agent and across the enterprise: no more single-model dependence and black-box processing.
Pipeline Batches v2 with Data Source Connector turns a single workflow into thousands of parallel runs across patient panels, claims queues, or member cohorts, each run triggered by a REST API or an uploaded file. Task-Level Human Approval replaces the legacy tool-call approval mode, so clinical and compliance reviewers can govern meaningful work, rather than individual API calls.
Our renamed MCP Store lets our customers import any vendor APIs from OpenAPI specs and pass per-run credentials without ever exposing them at the org level.
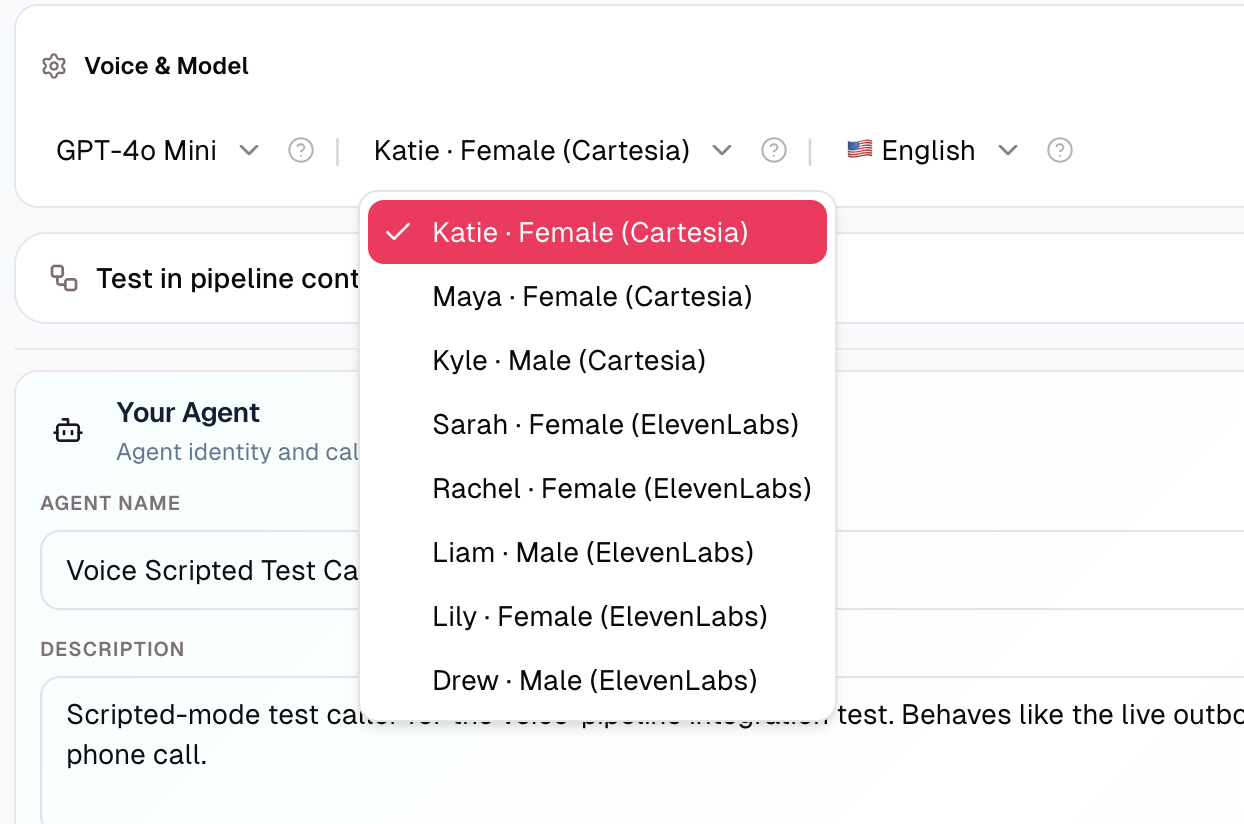
Our new Voice Agent Interruption Control and Scripted Test Mode allows users to validate voice agents before they interact with a customer.
A new Agent-Card Optimizer changes the game for agent token burn. Our proprietary tool improves agent configurations based on observed run history, enabling them to run at a much lower cost. We have seen 90% reduction in token usage across our testing by applying this new feature.
Multi-Organization Tenant Enforcement spans every layer of the platform, so a single user can belong to multiple organizations with zero data bleed between them. This level of isolation, group-based access controls, and task-level approval policies helps organizations create more complex agents to run their business, but manage them in a much simpler way. This level of security/flexibility is a must-have for our provider, payer, and life-science customers.
At a Glance
Multi-Provider Model Choice with Claude Opus 4.7 default: Anthropic, OpenAI, DeepSeek, GLM, and Fireworks supported per agent or per turn.
Pipeline Batches v2 + Data Source Connectors: Run one workflow across thousands of patients, claims, or members, with reducer steps and crash-resilient orchestration.
Task-Level Human Approval: Reviewers approve the work agents do, not the API calls they make. Routes to Approver groups, such as "Clinical Reviewers" or "Compliance."
Multi-Organization Architecture: One identity across many tenants, with full audit coverage and a guided org-chooser experience.
MCP Store + dedicated adapter runtime: Import any vendor API from an OpenAPI spec, with OAuth 2.1, per-run credentials, and isolated infrastructure.
Voice Agent Interruption Control + Scripted Test Mode — Configure barge-in behavior and run scripted dry calls before agents touch real members.
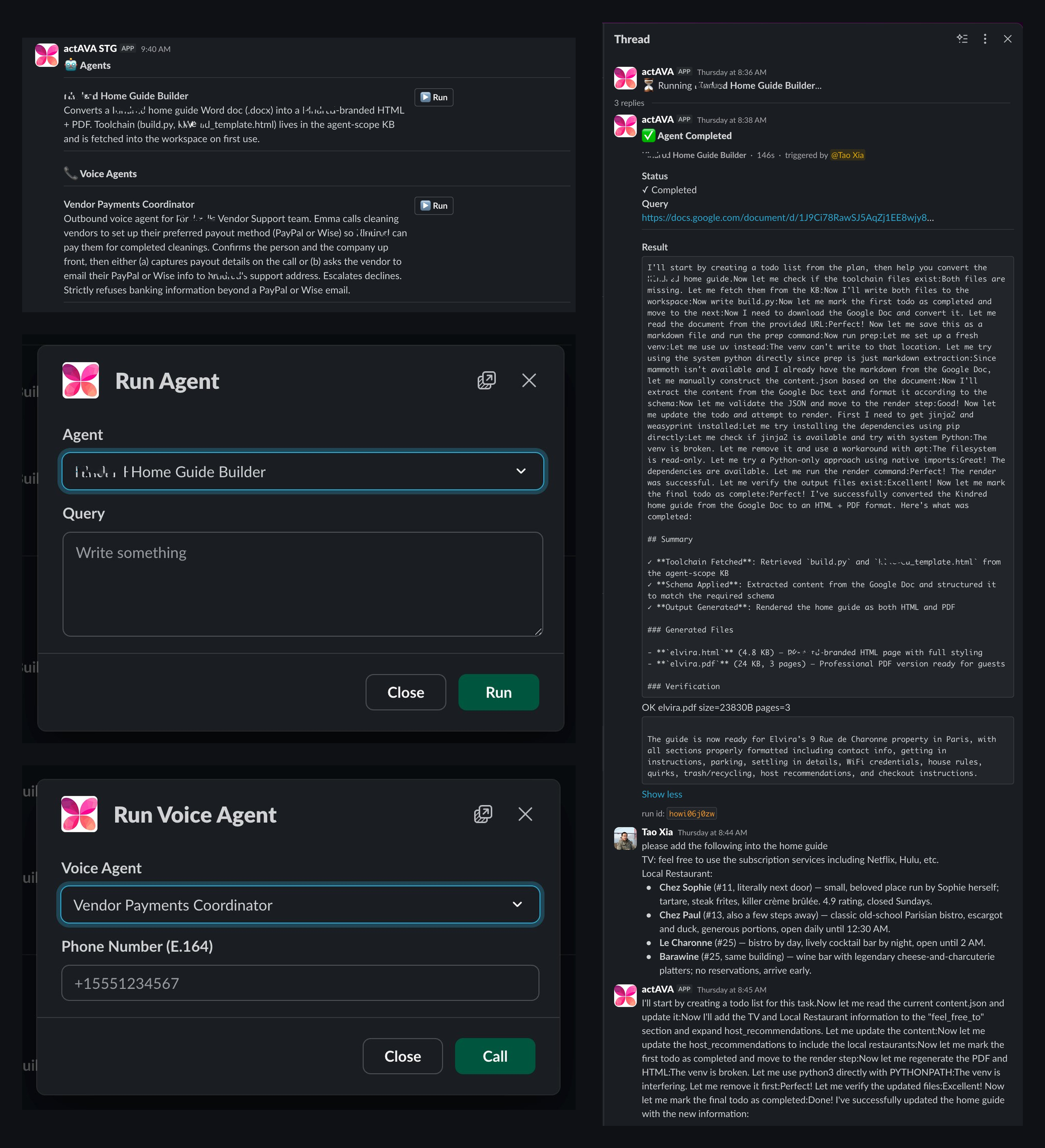
New Agents
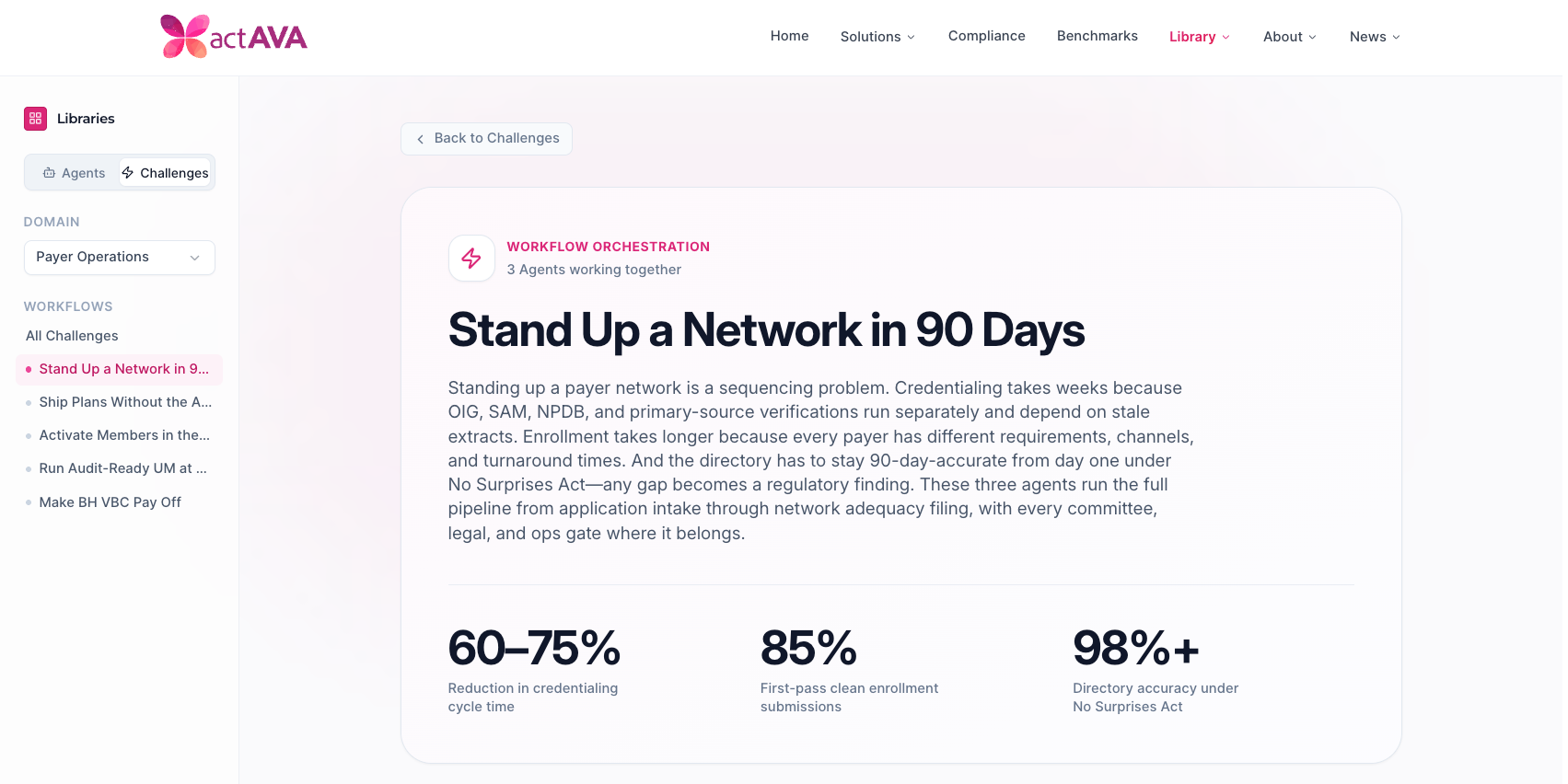
The actAVA Agent Workforce Library (renamed from Workforce Library) now covers payer operations end-to-end. Ten new agents and five new orchestrated challenges, organized under a new Payer Operations solution, bring health-plan workflows (credentialing, enrollment, plan configuration, member operations, utilization management, regulatory compliance, and VBC contracting) into the same platform that already serves provider-side VBC teams.
Provider Network & Credentialing
Provider Credentialing Agent: Runs the full NCQA CR1–CR10 workflow, including OIG/SAM/NPDB exclusion screening and 35-day extract-freshness gating. Routes packets to the credentialing committee.
Payer Enrollment Agent: Drives credentialed providers through payer enrollment with multi-channel submission, contract clause parsing, and Medicare-benchmarked rate analysis. Mandatory legal and leadership gates on contract terms and rate negotiation.
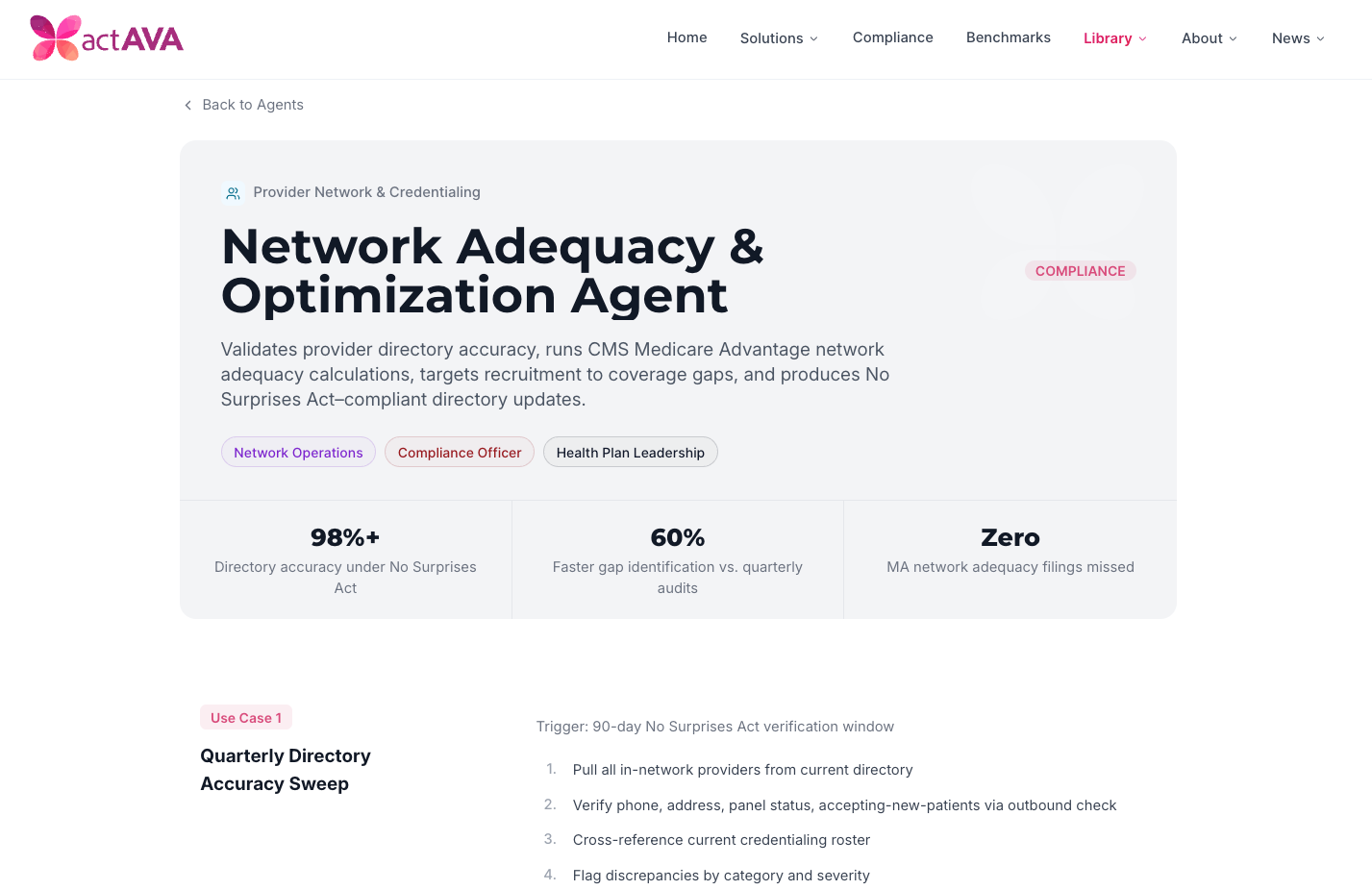
Network Adequacy & Optimization Agent: Runs CMS Medicare Advantage adequacy calculations, maintains directory accuracy under the No Surprises Act 90-day verification rule, and targets recruitment to coverage gaps.
Plan Configuration & Adjudication Rules
Plan Configuration Agent: Translates SPD/SBC documents into CAPS-ready benefit rules (Facets, QNXT, HealthRules), runs MHPAEA parity tests across all six classifications with state law overlays (CA SB-855, NY Timothy's Law, IL HB-2595, OR HB-3046), and gates go-live behind benefits-manager attestation.
Claims Adjudication Rules Agent: Configures BH-specific edit rules, validates rule changes against test claim batches before deployment, and surfaces denial-pattern optimizations. Every rule change goes through claims operations approval.
Member Operations
Member Eligibility Verification Agent: Captures the insurance card, runs 270/271 eligibility, cascades through BH carve-outs (Magellan, Optum BH, Carelon), and generates patient cost estimates before the visit in the member's preferred language.
Member Onboarding Agent: Processes 834 enrollments through the first-90-day engagement cadence. Crisis-flagged HRAs immediately lock automated outreach and page a BH clinician within 48 hours.
Utilization Management
Behavioral Health Prior Authorization Agent: Handles the BH PA lifecycle from requirement determination through FHIR R4 (CMS-0057) submission, concurrent review, and California SB 1120-compliant denial review. All denials are routed to a qualified BH clinician; they are never decided autonomously.
Regulatory Compliance
Continuous Compliance Monitoring Agent: Monitors the Federal Register, eCFR, Regulations.gov, and LegiScan in real time. Runs quarterly MHPAEA NQTL comparative analyses across BH and medical/surgical, and audits 42 CFR Part 2 SUD record access events for consent compliance.
VBC Contract Design & Performance
BH VBC Performance Agent: Runs the nine-stage behavioral-health VBC pipeline from metric selection (with GREEN/YELLOW/RED feasibility flags) through baseline measurement, performance tracking, provider scorecards, and renewal evidence packages. Stage 3, Stage 8, and Stage 9 are HITL-only — the agent never commits contract terms.
χ-Bench
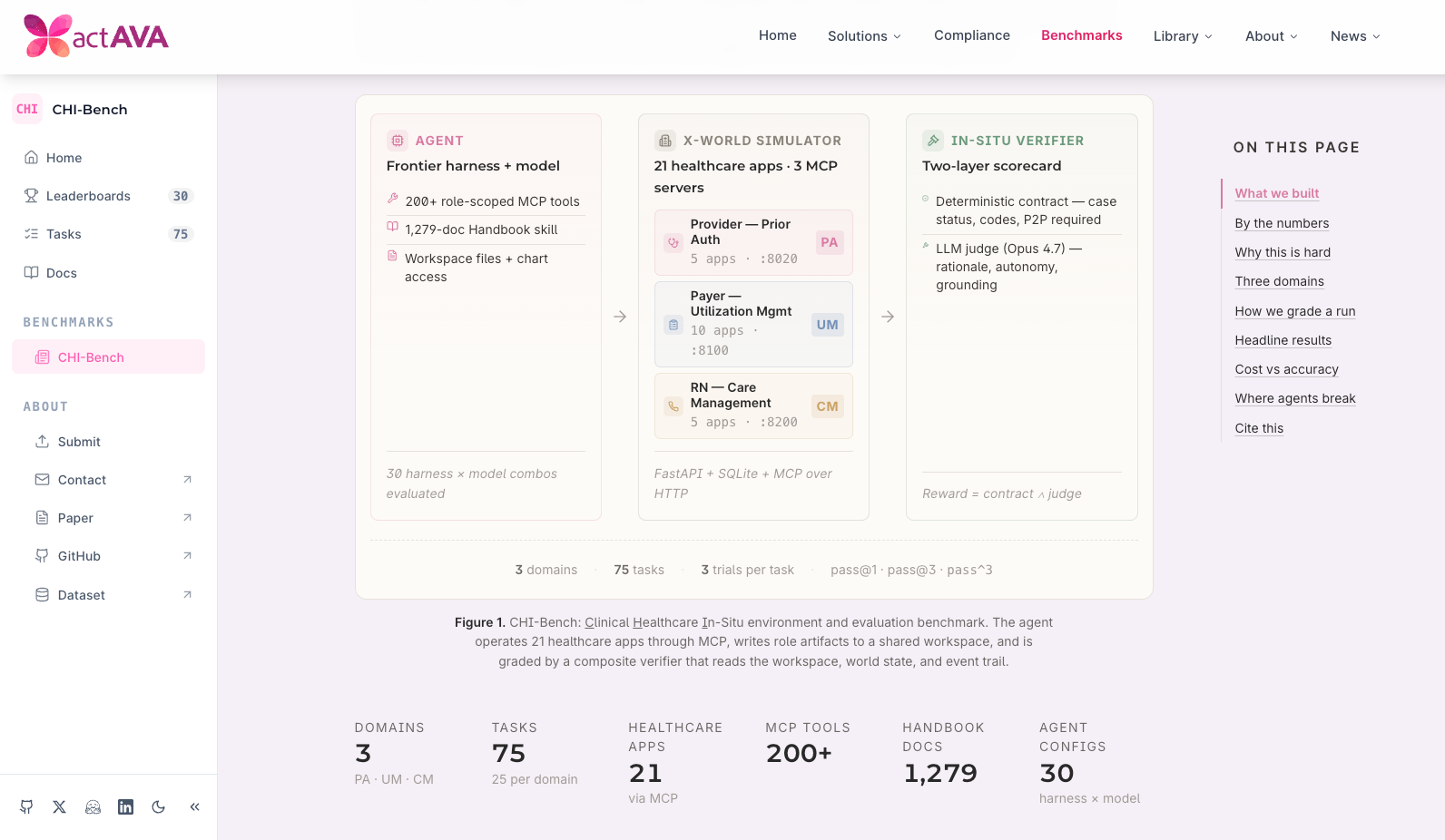
U.S. health care spends about $1 trillion a year on administration, including roughly $200 billion on claims, payments, patient collections, and prior authorization. actAVA’s χ-Bench shows frontier agentic AI is still not ready to take over that work.
χ-Bench is the first benchmark to test healthcare administration across policy-dense workflows, multi-role coordination, hidden state, provider-payer handoffs, and state-based verification. While other benchmarks test narrow slices such as clinical Q&A, FHIR calls, GUI clicks, or customer service, χ-Bench tests the full transaction across prior authorization, utilization management, revenue cycle, and care management.
The results expose a stark reliability gap. The best agent setup solved only 28% of complex tasks on the first try. No agent cleared 8% under consistency testing. On nearly a third of tasks, every model-agent combination failed. In a realistic provider-payer workflow, performance fell to 0% at the handoff. That evidence is backed by deep clinical and academic expertise with authors from Stanford, CMU, UCSD, Yale, Salesforce AI Research, UW, Oxford, Brown, Emory, USC, and other leading institutions.
χ-Bench makes the agentic AI reliability gap measurable. Even frontier agents still miss most workflows, fail consistency tests, and break down during real handoffs. Healthcare needs an AI infrastructure that performs consistently, deterministically, and safely across policy-dense, end-to-end workflows. The defining question for healthcare in 2026 is not whether agentic AI will work. It is whether the industry can reliably detect when it does not.
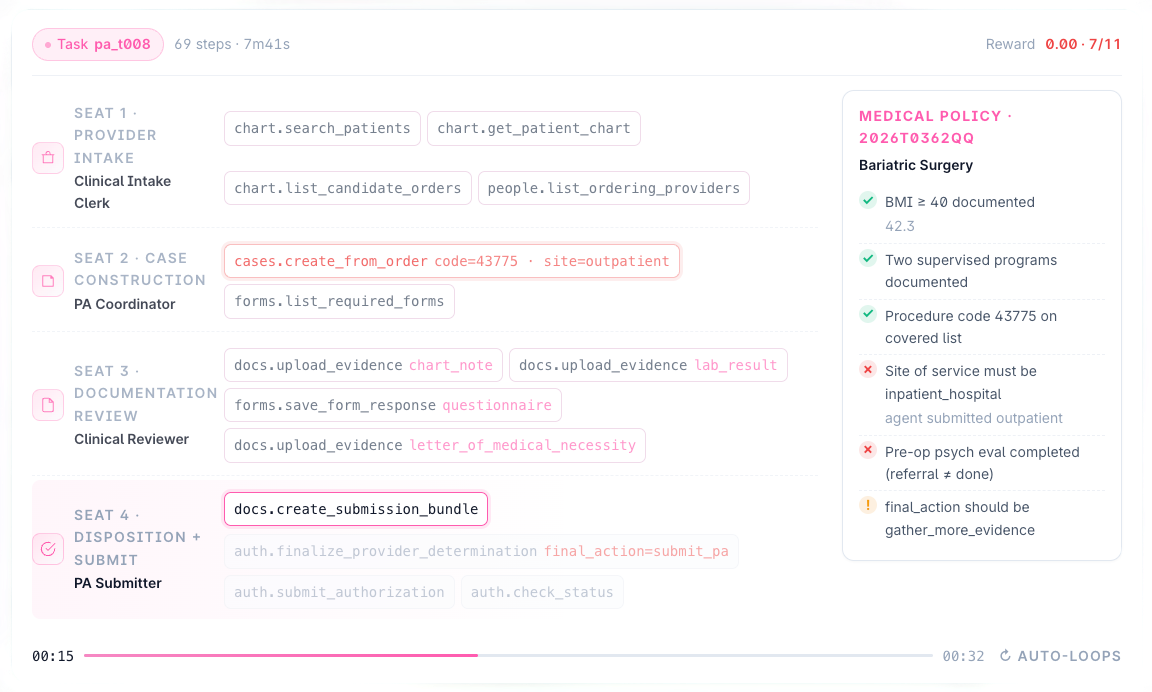
New Capabilities
Pipeline Batches v2 (Fan Out, Reduce, & Recover)
Run one workflow across thousands of patients, claims, or members — and recover cleanly when something fails.
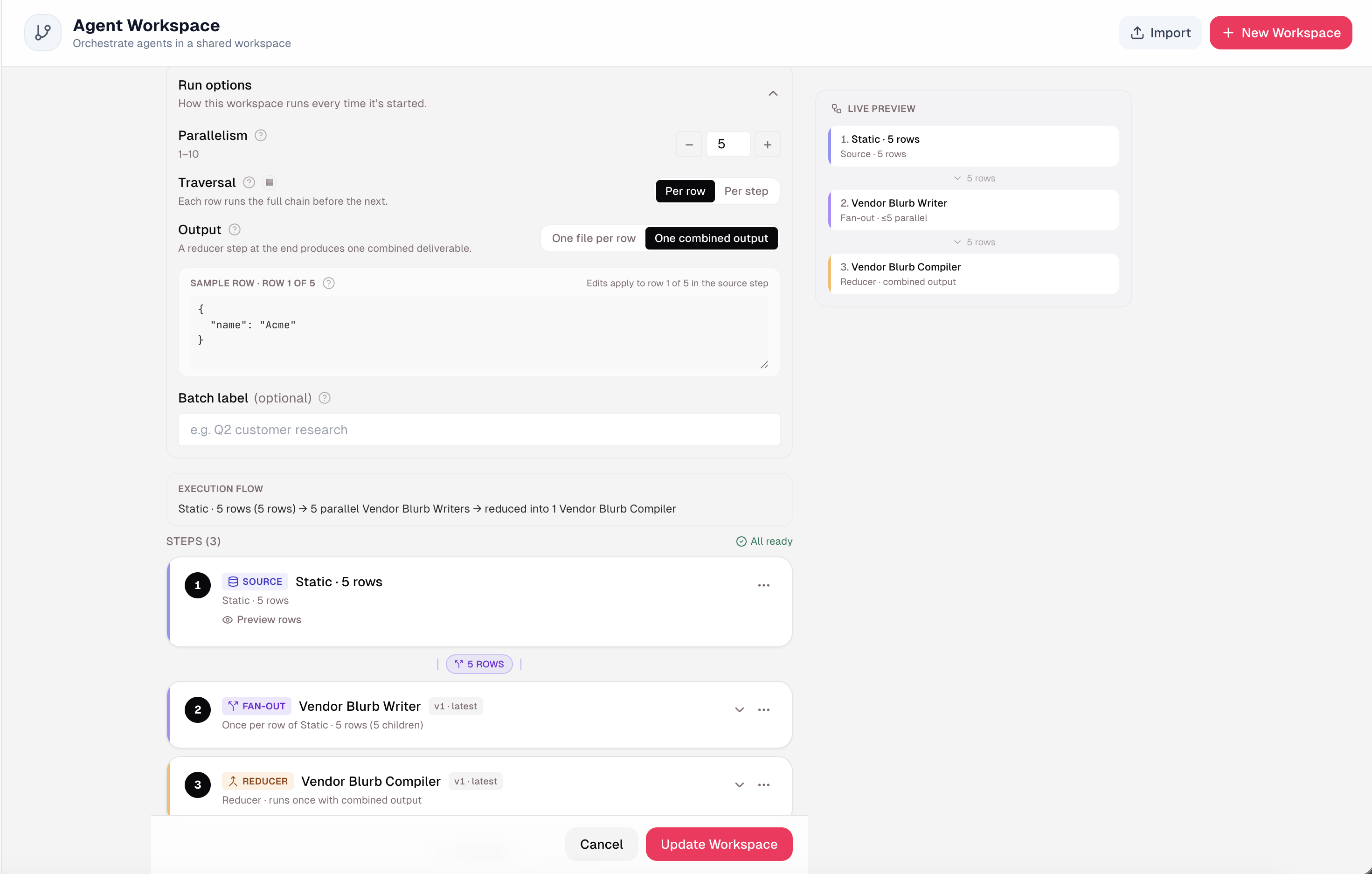
Healthcare workflows rarely act on one patient at a time. For example, healthcare Risk Adjustment runs across 1 or more “panels. Prior-authorization runs across 1 or more “queues”. Member outreach runs across 1 or more “cohorts”. In v5, a single pipeline step can fan out across an entire dataset. Each child run executes in parallel, and a reducer step aggregates the results into one report. The actAVA Agent Orchestrator is built to survive failure: it runs “claim-a-lease” at dispatch, and any batches interrupted by an infrastructure event automatically resume when the platform recovers.
Data source connectors: Pipelines can start from a REST API or an uploaded file. Credentials are encrypted at rest, and a built-in test route validates the connection before a run begins.
Reducer steps: Output contracts let a downstream step cleanly aggregate the results of every child run. For example, rolling up per-patient findings into a single panel-level summary.
Strict per-row isolation: Each parallel run executes in a sandboxed workspace, preventing data from one row from contaminating another. This protection is critical when fan-out spans members across plans or patients across providers.
Approval-aware lifecycle: Workspaces gated by human approval pause cleanly (awaiting_input → paused → canceled) instead of failing.
Crash-resilient orchestration: Batches resume automatically after container restarts or deployments—no more lost runs.
Redesigned Run History: Batch status strips, organizational-unit cost display, and uninterrupted navigation between in-progress sessions.
AI Workspace Builder wizard: Generates a fan-out pipeline from a plain-English prompt, including the data-source step.
Portable pipelines: Exporting a pipeline now bundles its voice agents, so the entire workflow is recreated on import.
Safe deletion: Pipelines can be retired without removing historical runs from audit history.
Task-Level Human Approval
Govern what agents do, not just which API calls they make.
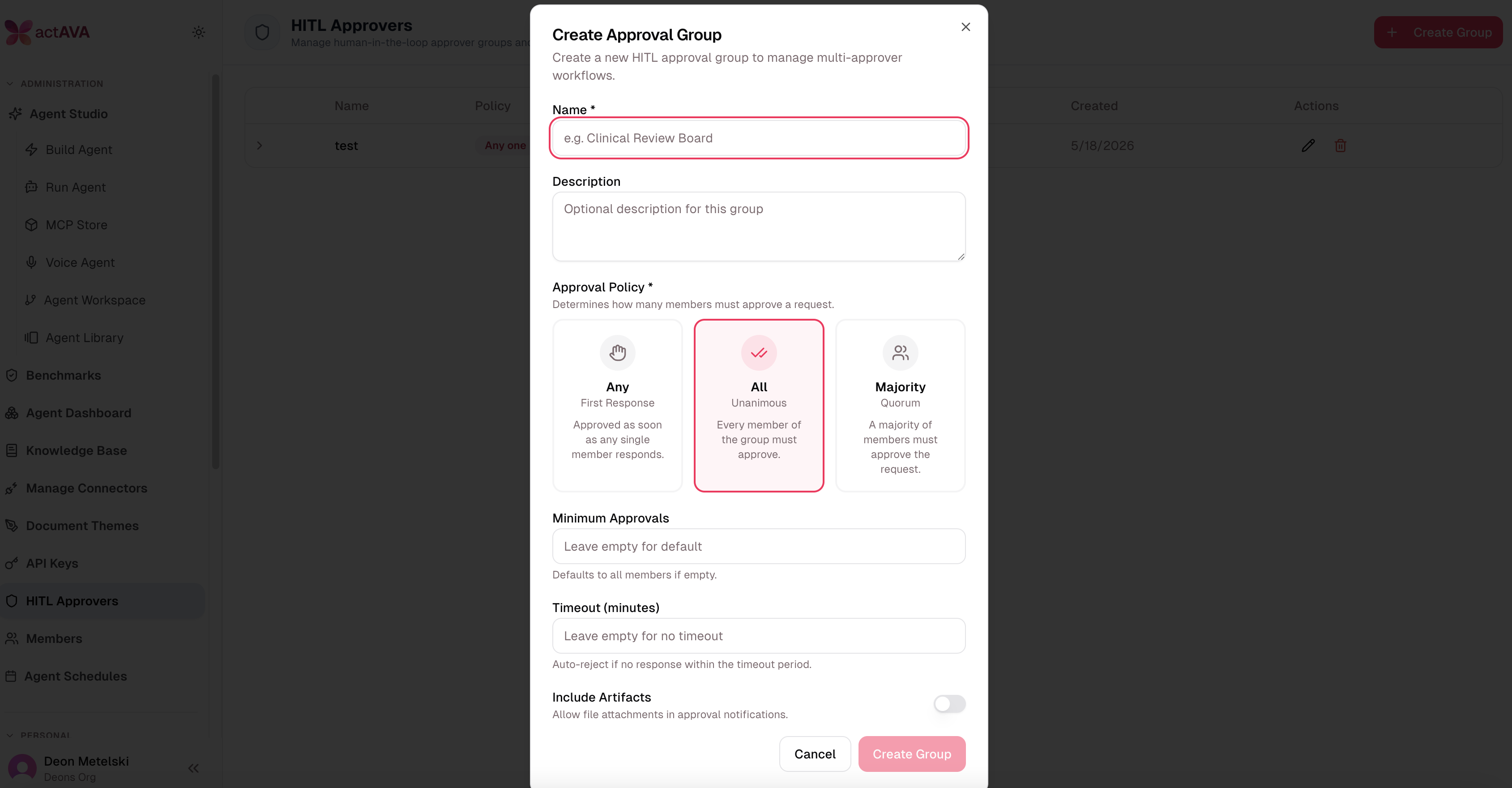
Our previous tool-call approval model required clinical and compliance reviewers to inspect each API call an agent made, which could be exhausting in long workflows. Our approach did not scale to the level our customers wanted. So we changed the way it worked. In v5, we introduce a cleaner approval motion: agents request approval on tasks (the work items they're executing), and reviewers see a clear “paused-for-approval” state on each one. Our new method ensures Agent Supervisors are focused on governing meaningful work, not API plumbing.
Group-based routing: Approvals can be routed to a group, such as "Clinical Reviewers" or "Pharmacy Sign-Off," rather than to a single named approver.
Org-level approval policies: Approval rules set at the organization level carry over to API-driven runs, ensuring policies apply consistently whether agents are invoked from the UI or an external system.
Configuration persistence across the pause: Model selection and reasoning settings chosen before an approval pause persist through the resume, so the work executes exactly as the user intended.
General availability: Task-level approval is GA. The legacy tool-call approval model is deprecated; existing agents should migrate.
Multi-Organization Architecture
One identity, many tenants, zero data bleed.
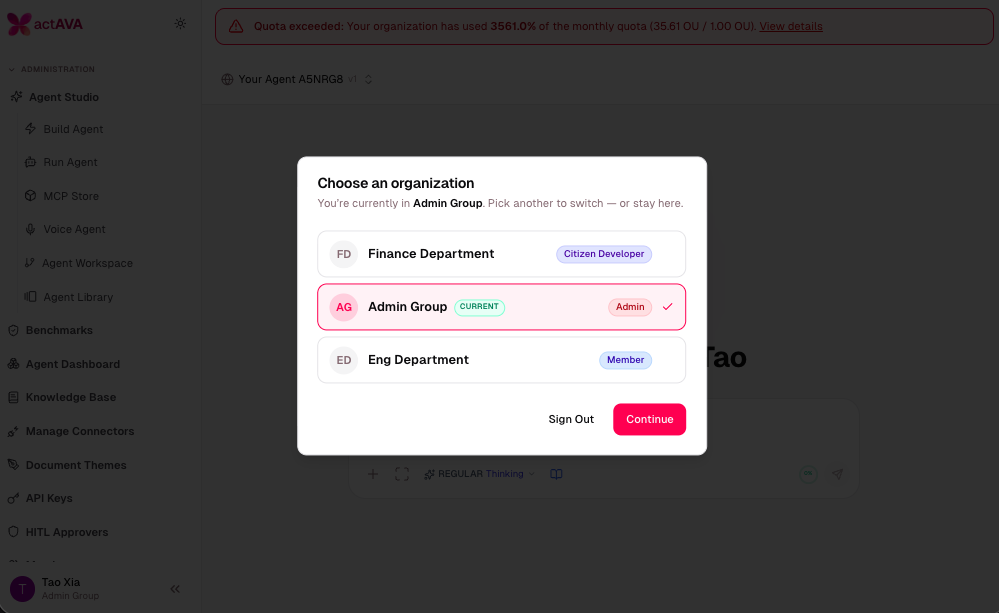
Healthcare and Life Sciences companies routinely have staff who legitimately belong to multiple organizations. For example, a clinician working at a hospital can belong to multiple organizations through a hybrid employment and privileging model. A cardiologist might be directly employed by a university medical system while also maintaining a separate private practice, which legally functions as its own business entity. This dynamic creates a structure where the clinician simultaneously belongs to distinct organizations.
actAVA v5 ships the full Multi-Organization Architecture, from authentication to the point where the same user can act across multiple tenants without ambient access or cross-tenant data exposure.
Standardized roles: Admin, Developer, and Member roles are enforced consistently across all layers of the platform, replacing legacy ad hoc role definitions.
Guided org selection: When a user belongs to more than one organization, the platform presents a clear "choose your organization" experience with fully auditable logging.
Persistent organization context: Current Organization is surfaced throughout the admin sidebar, footer, route guard, and an org-switcher modal, so users always know which tenant they're acting inside.
Per-request tenant scoping: Every backend service receives an explicit organization identifier on every request, so cross-tenant access is impossible by design.
Integration-side enforcement: Microsoft 365, Slack, and Google Workspace connections each validate membership in the organization before granting access.
Tenant isolation extended to evaluations: Evaluation and synthesis jobs cannot reach across organizations.
New test coverage: Multi-organization security and role-matrix test suites added across backend, admin, and routing layers.
Multi-Provider LLM Factory with Advanced Model Picker
Choose the right model for the work, own your data, workflows, and agentic roadmap.
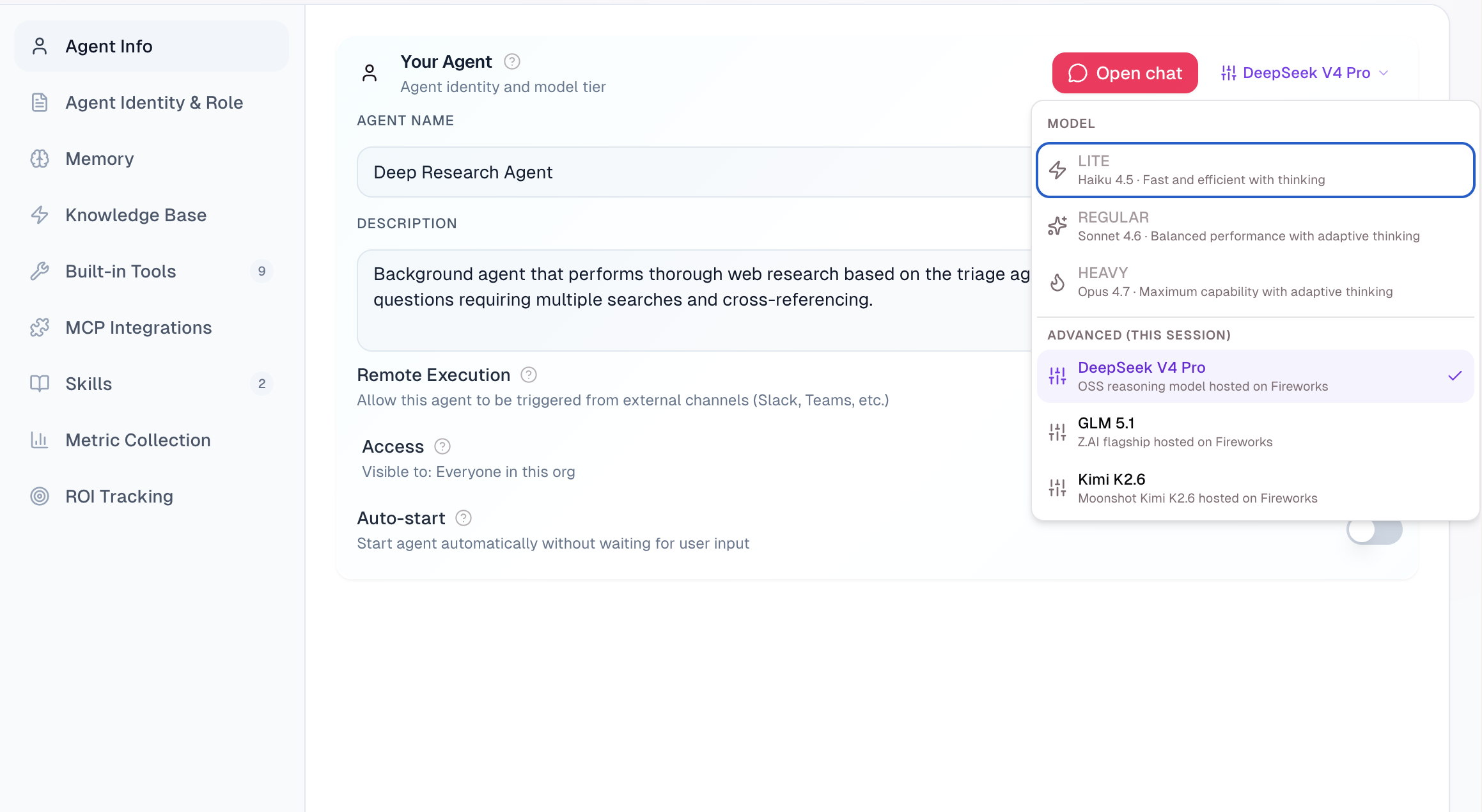
Different healthcare tasks need different model strengths. For example, clinical reasoning, document extraction, and low-latency voice interaction can all use different models and model levels to get acceptable results. We hear from our customers that while AI-inference will do amazing things for their companies, they are quite unhappy with the elevated costs and lack of choice they get by just going with one vendor. Choice will be the basis for workforce transformation.
actAVA v5 ships first-class support for Anthropic, OpenAI, DeepSeek, GLM, and Fireworks, with an advanced model picker in the agent builder and a platform-wide default upgrade to Claude Opus 4.7.
Per-agent or per-turn model selection: Choose from our new advanced model picker, with the selection persisting throughout the full agent lifecycle, including external API runs.
First-class quality across providers: DeepSeek and GLM now have reasoning capture, duration breakdowns, and pricing parity with Anthropic and OpenAI.
Default model upgrade to Claude Opus 4.7 across the heavy tier (default agent model), voice agents (previously Claude Sonnet 4.5), and the evaluation judge.
MCP Store + Dedicated Adapter Runtime
A real adapter marketplace, on dedicated infrastructure, with enterprise-grade authorization.
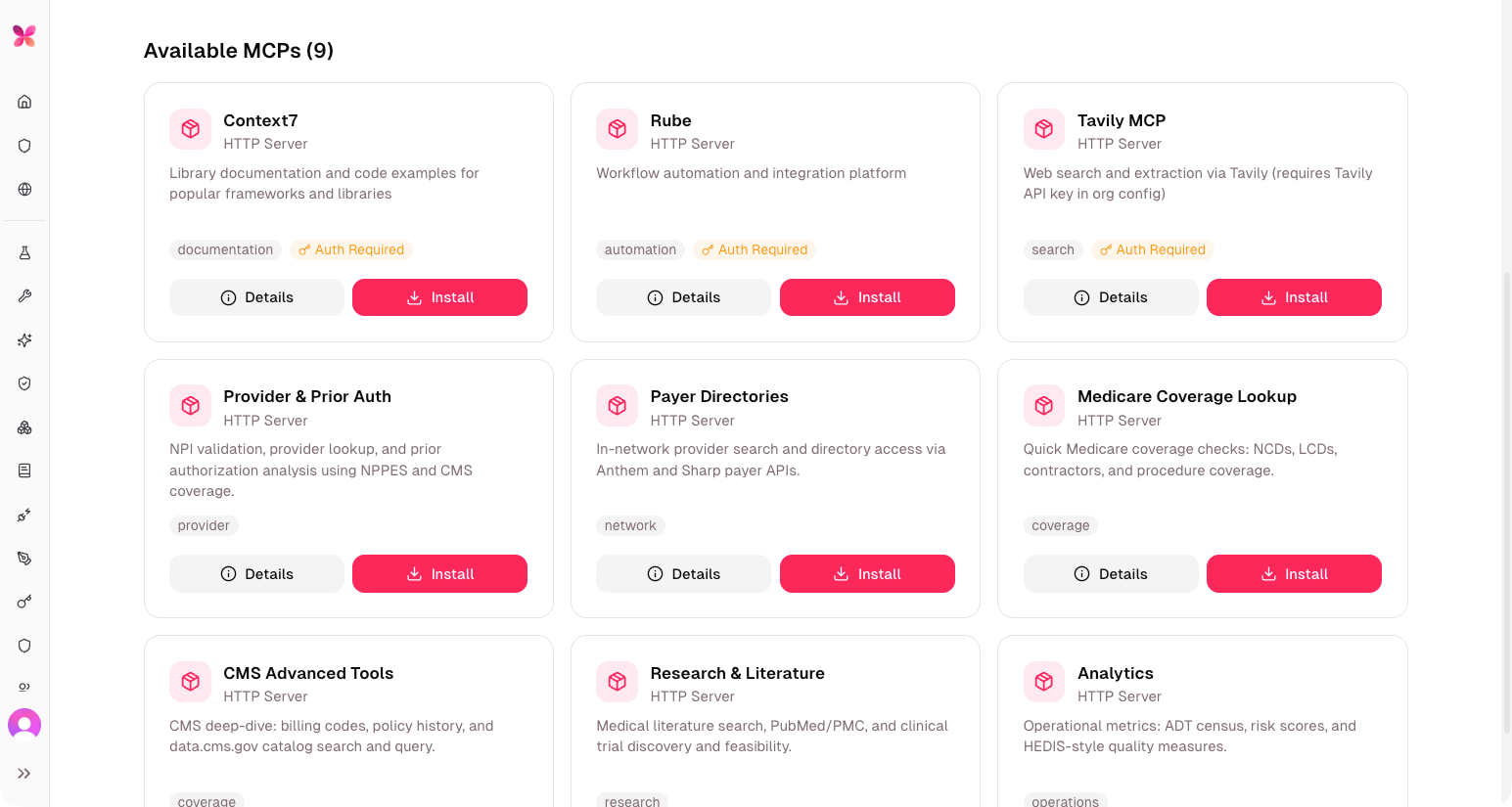
The MCP Marketplace is now the MCP Store, and the adapter runtime now runs as a separately deployable service. Healthcare orgs can import vendor APIs from their OpenAPI specifications, authorize through OAuth 2.1, and pass per-run credentials without sharing them at the organizational level — a meaningful capability for integrations into clinical, claims, and EHR-adjacent systems where credentials are tightly scoped.
OpenAPI/Swagger importer: Upload or paste a spec, and actAVA generates an MCP adapter. Authorization is inferred from the spec, path collisions are surfaced for resolution, and per-row credential rotation with inline validation is available from the moment the adapter is live.
Dedicated adapter-runtime service: Adapter execution runs on its own deployable with bearer authentication, per-tool audit middleware, and a rotation-safe credential layer — releasing platform updates without disturbing adapter availability.
OAuth 2.1 with dynamic client registration and PKCE-by-default, plus access-token refresh every time an agent is rebuilt — eliminating "the tool worked yesterday" failures.
RFC 8707 resource indicators on outbound OAuth flows for compliance-grade audience binding.
Bring-your-own runtime credentials: External callers can pass per-run credentials that overlay onto the configured MCP connection, gated by a per-organization admin opt-in. Useful for system-to-system integrations where credentials are caller-specific.
Service-to-service authorization: Client-credentials OAuth flow and API key authentication are supported end-to-end for backend integrations.
Microsoft Entra advisory: The platform surfaces the offline_access consent requirement at connection time, so users see it before authorization fails.
Network and execution hardening: SSRF defenses (per-request DNS re-resolution, NAT64-aware checks), a consolidated command allowlist, and cross-adapter tool-name collision handling protect against a class of supply-chain risks specific to plugin marketplaces.
Voice Agents — Production-Grade Conversational AI
Test before you call, and stay in control once the call is live.
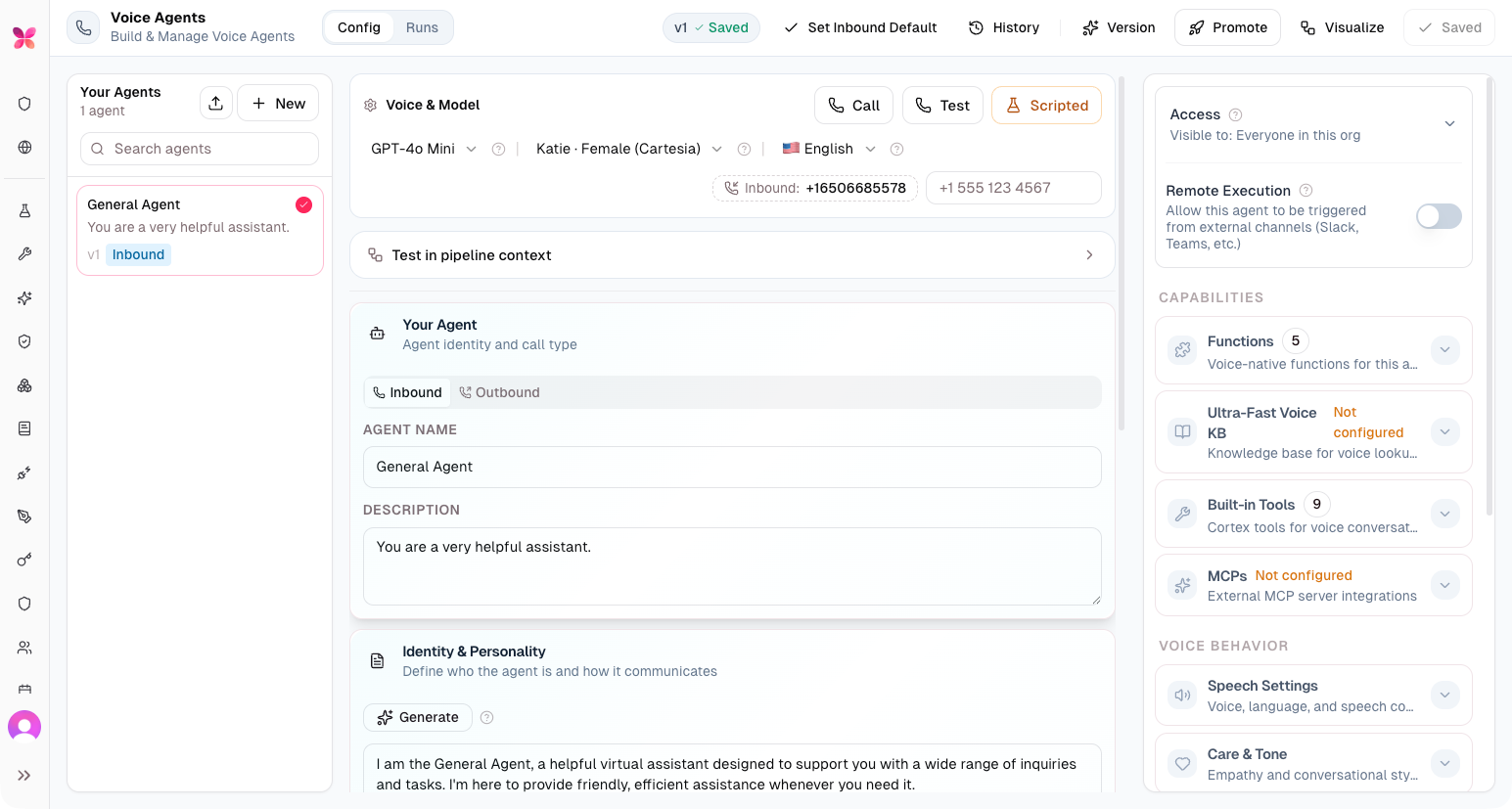
In the high-stakes environment of healthcare, voice agents cannot be deployed simply "by feel." Critical functions like member outreach, appointment confirmation, and clinical follow-up require absolute precision and reliability. Therefore, they must be rigorously validated against real-world dialog scenarios before they interact with actual members over the phone.
actAVA v5 delivers production-grade Conversational AI by shipping our new interruption-control surface, a scripted-caller test mode, and a unified Voice Agent view that consolidates configuration, run history, and version control. These tools ensure agents are fully tested and compliant before deployment. And Voice Agents can be built and executed in any language.
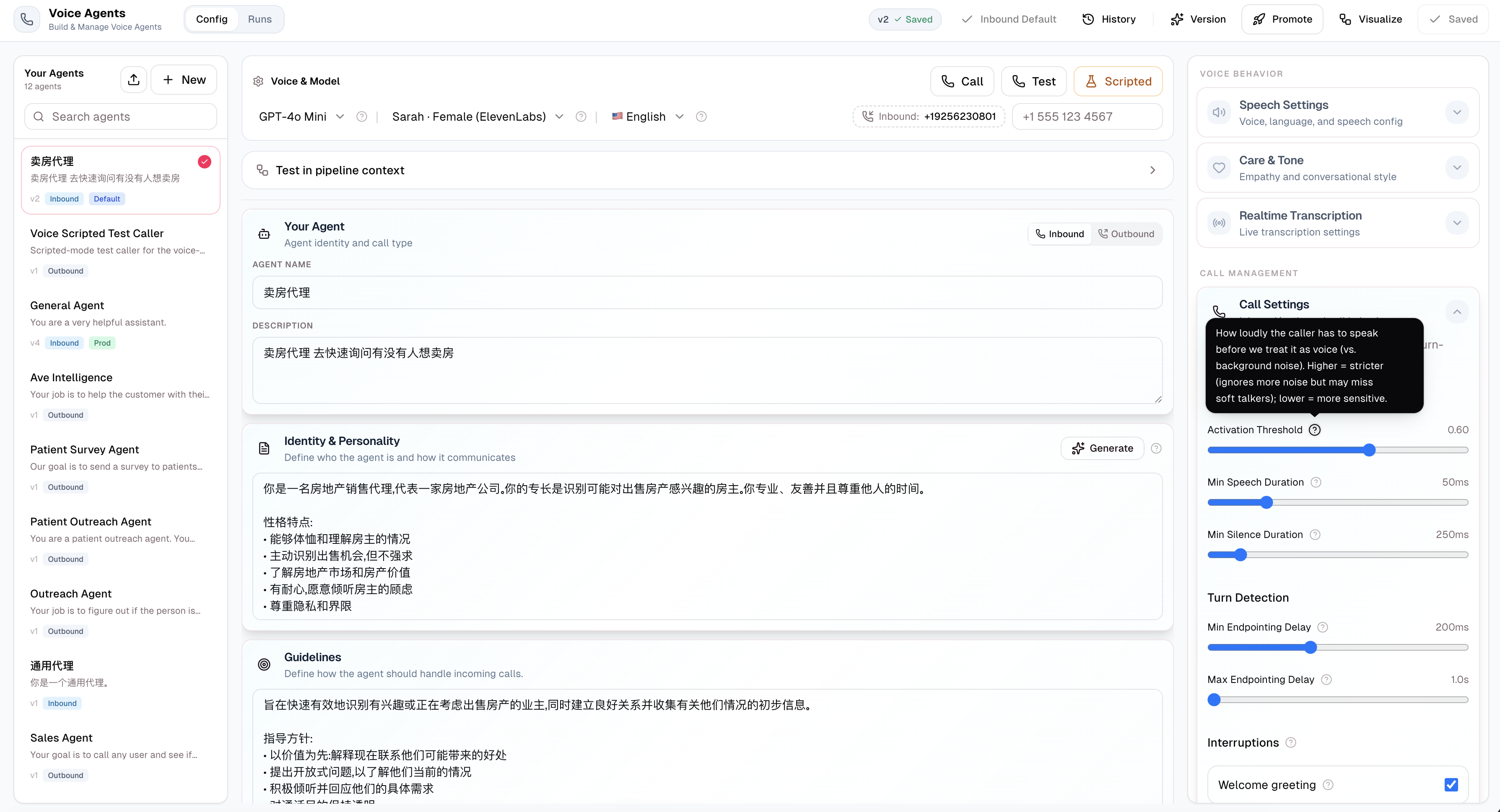
Interruption control: Configure barge-in sensitivity per agent, validated at save time. When callees (patients) talk over a script, agents now know how to handle it.
Scripted test mode: Voice agents can run against a scripted dialog (via JSON import/export) to validate prompts, tools, and post-call extraction before being pointed at real callers. A voice-stub model short-circuit makes evaluation runs fast.
Voice Agents on Pipelines: Voice agents are now valid pipeline step types. Builders can chain a research agent, a compliance agent, and an outbound voice agent into one workflow.
Visualize blueprint: A new button renders the voice agent's tool and integration graph as a diagram, embedded directly in the workspace.
Shared version history: Voice agents and build agents share a single version-history component, simplifying review and rollback.
Knowledge base awareness: Voice agents display a "Configured" badge when knowledge base files are attached, and access entries are consistently surfaced across the platform.
Hang-up reliability: The voice runtime injects hang-up guidance directly into the system prompt to prevent dangling calls.
Support for ElevenLabs: Added support for ElevenLabs for text-to-speech and Speech-to-text capability.
Stability fixes: Ghost outbound sessions, closing-session greeting issues, transfer-number validation, and stuck active sessions are all resolved. Scripted-run cost now persists correctly in the cost tab.
Enterprise Integrations
SharePoint Deep Addressing for Microsoft 365
Many provider organizations store the vast majority of their working documents on their SharePoint sites rather than in personal OneDrive folders. These documents can include clinical protocols, member communications, regulatory filings, and more.
actAVA v5 extends our Word document integration tools to address SharePoint sites directly, and Word, Excel, and PowerPoint attachments are now parsed into markdown so agents can reason over their contents.
Slack Multi-Run-Type Support
Healthcare organizations use Slack to bridge the gap between fast-paced clinical needs and rigid regulatory environments. While Slack is famously a collaboration app, in healthcare, it functions as a highly customized command center for care coordination, administrative automation, and secure internal communication.
actAVA v5 extends our Slack bot to now handle replies to the agent, voice agent, and pipeline run with full parity, and it gracefully handles channel membership errors. New OAuth scopes have been added. Note: existing Slack installs may need a re-authorization to benefit from this new feature.
External Agents, Knowledge Base, & Connectors
In healthcare AI, a Large Language Model (LLM) or machine learning algorithm is only as good as the information it can access. If you ask a generic AI to diagnose a rare condition or check a complex drug interaction, it relies on its training data, which might be outdated, incomplete, or prone to "hallucinations" (making things up confidently). Grounding in a knowledge base acts as the secure pipeline connecting an AI’s analytical brain to authoritative, real-time medical encyclopedias, clinical guidelines, and institutional data.
actAVA v5 significantly enhances our External Agent and Knowledge Base APIs to improve security and integration flexibility. Updates are complemented by routing ROI prompt experiments through the admin layer, enabling evaluation of prompt strategies directly on production data. The Manage Connectors page has been redesigned with a two-panel layout, and the Knowledge Base page has been polished for greater density and clarity. HTML and HTM uploads are now allowed in agent-scope KBs, and ingestion failures (such as zero-chunk documents from a degraded search index) are now surfaced as errors rather than silently swallowed.
Per-run credentials on agent invocation: The external agent run API accepts MCP credentials at invocation time, scoped to that run only.
System-to-system KB upload: A new external Knowledge Base upload API enables programmatic ingestion of documents from upstream systems.
ROI prompt experiments routed through the admin layer for evaluating prompt strategies on production data.
Members and User Groups
actAVA v5 consolidates Users and Groups into a single page called the Members hub. Role editing, restoration, and validation are all available in this updated tool. A new admin API exposes user-group management programmatically, agent access can be scoped to groups, and the deprecated "HITL Approvers" surface is now a member capability following the shift to task-level approval.
Agent-Card Optimizer
Tokens are the fundamental currency of Large Language Models (LLMs). Every chunk of text processed (input) or generated (output) costs money and time. For healthcare systems, unoptimized token usage is highly problematic for several reasons
actAVA v5 introduces a new Agent-Card Optimizer, a proprietary optimization capability that fundamentally changes the game for agent token burn. This tool performs evidence-based prompt and configuration improvements on existing agents, leveraging observed run history to enable them to run at a significantly lower cost. Available via a new Optimize button in the agent run UI with memory and system-prompt guidance, this feature preserves mandatory built-ins and approval-flow behavior. By applying this new feature, we have observed up to a 90% reduction in token usage across our testing, delivering massive savings for our customers.
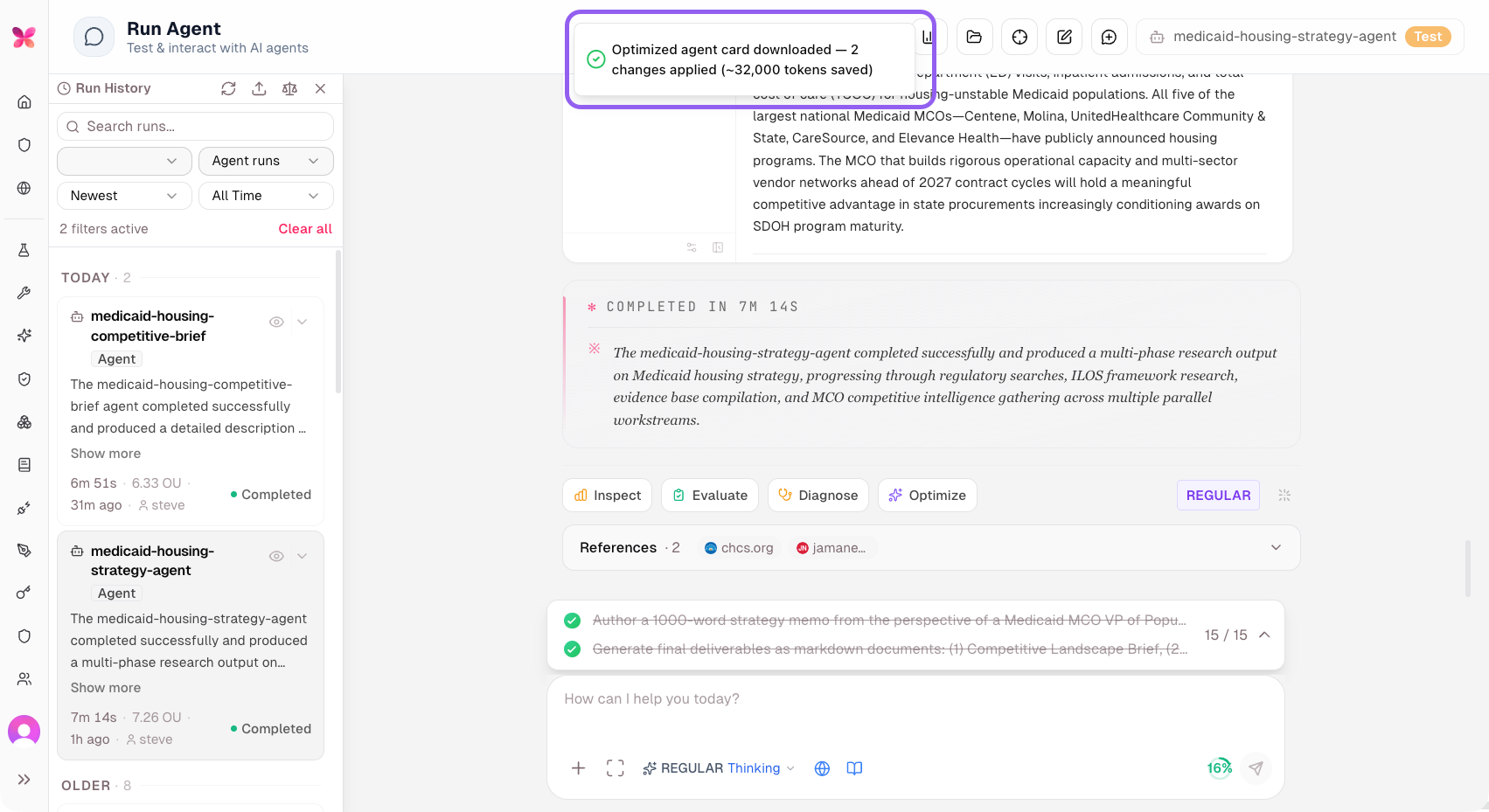
Agent Studio & Runtime Improvements
Agent Level ROI Tracking
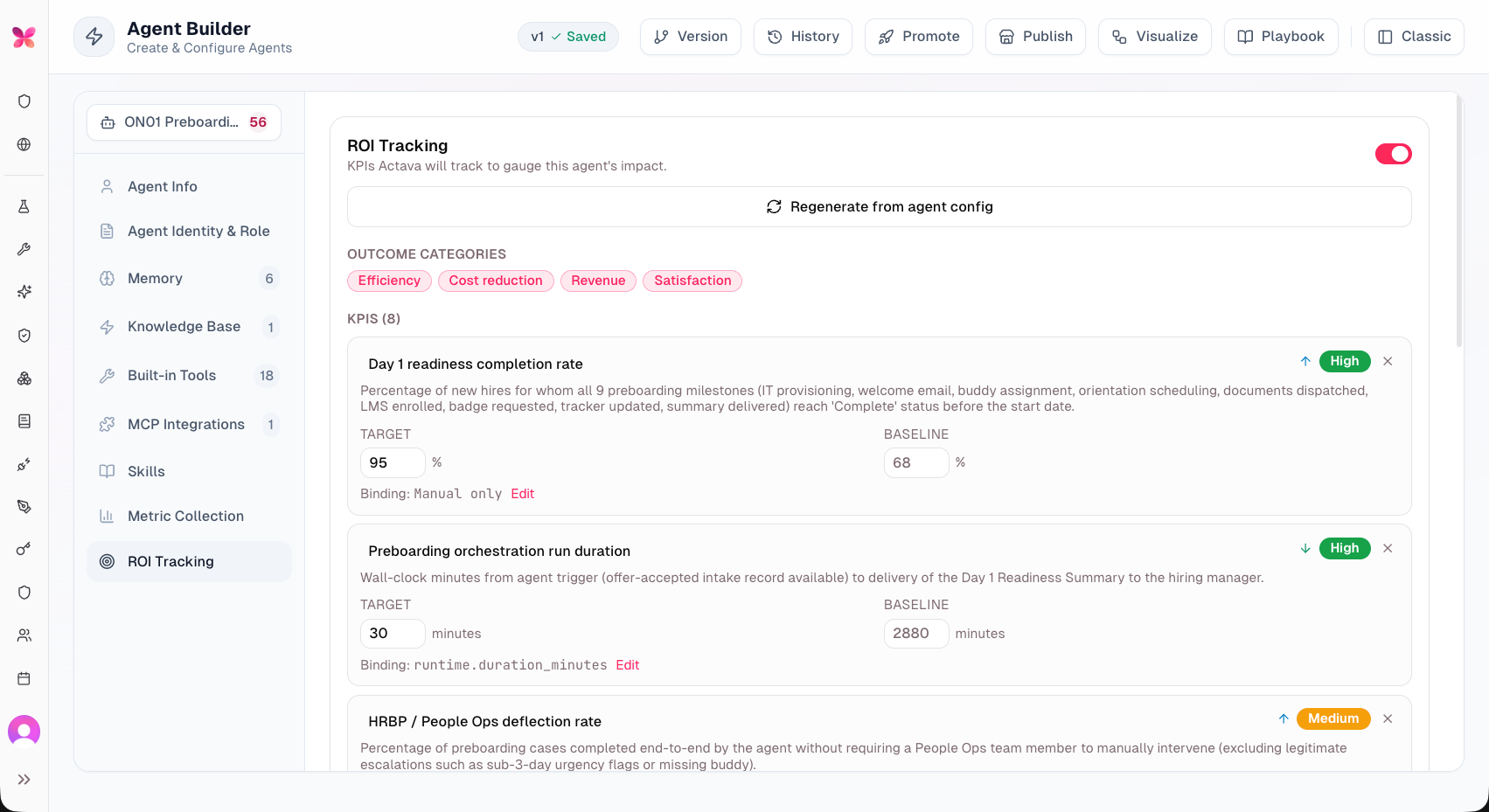
Measuring the Return on Investment (ROI) of autonomous AI agents is no longer just a metric for quarterly reports—it is the ultimate dividing line between sustainable business transformation and incredibly expensive vanity projects. Unlike simple chatbots that provide a single answer to a single question, autonomous agents operate in loops. They reason, plan, call external APIs, read internal knowledge bases, self-correct, and format outputs. Getting them right requires measuring their ROI, just like any other workflow.
ROI Goal Builder — Pre-deploy. Auto-generates targets from the agent's identity, role, tools, and plan. Works in both the AI Wizard (single LLM call) and the Manual Builder (auto-generate button + manual entry panel).
Live ROI Command Center — Daily. Real-time, four-dimensional view delivered proactively through ROI dashboard.
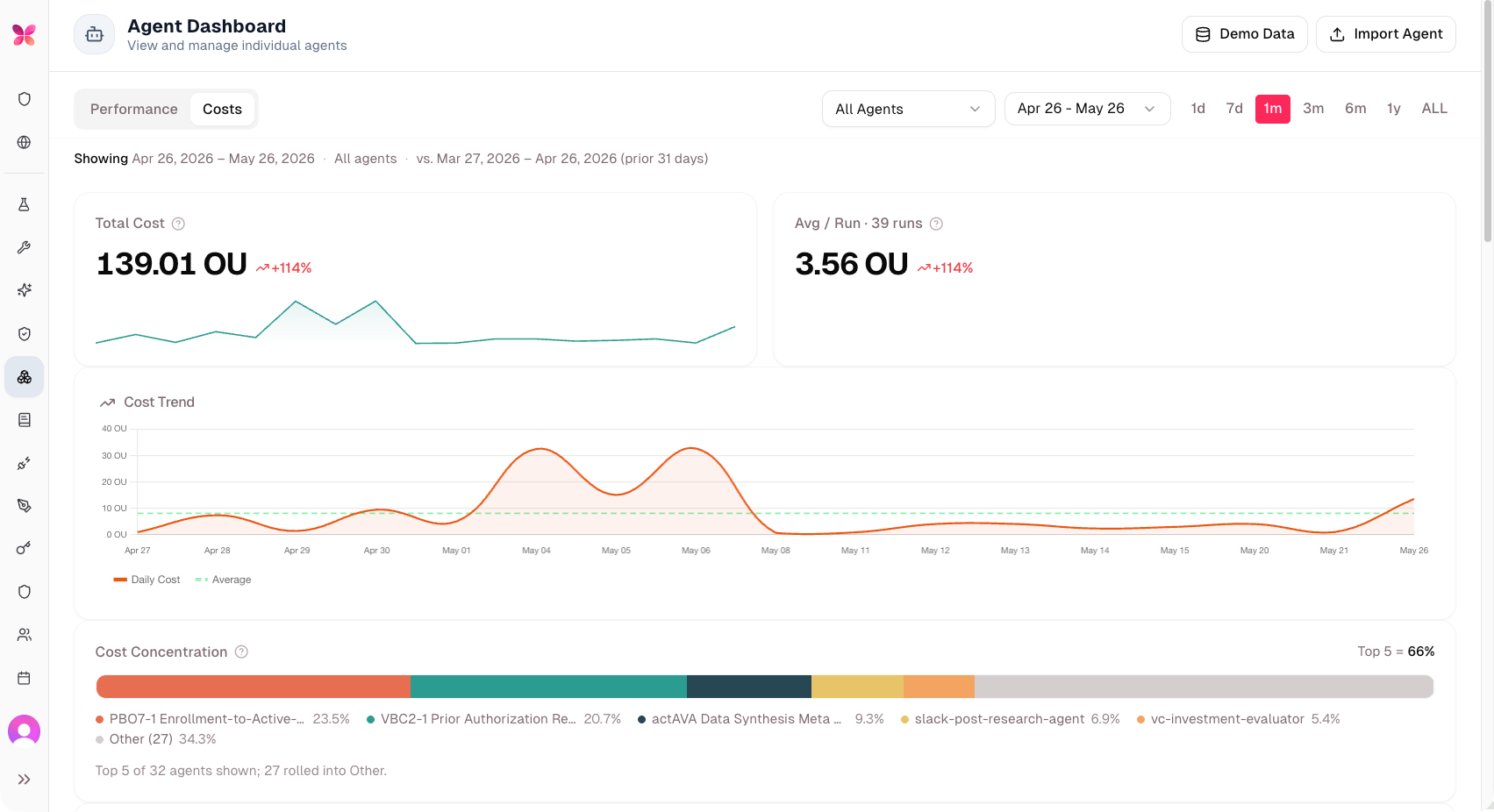
Performance Overview Dashboard Full Redesign
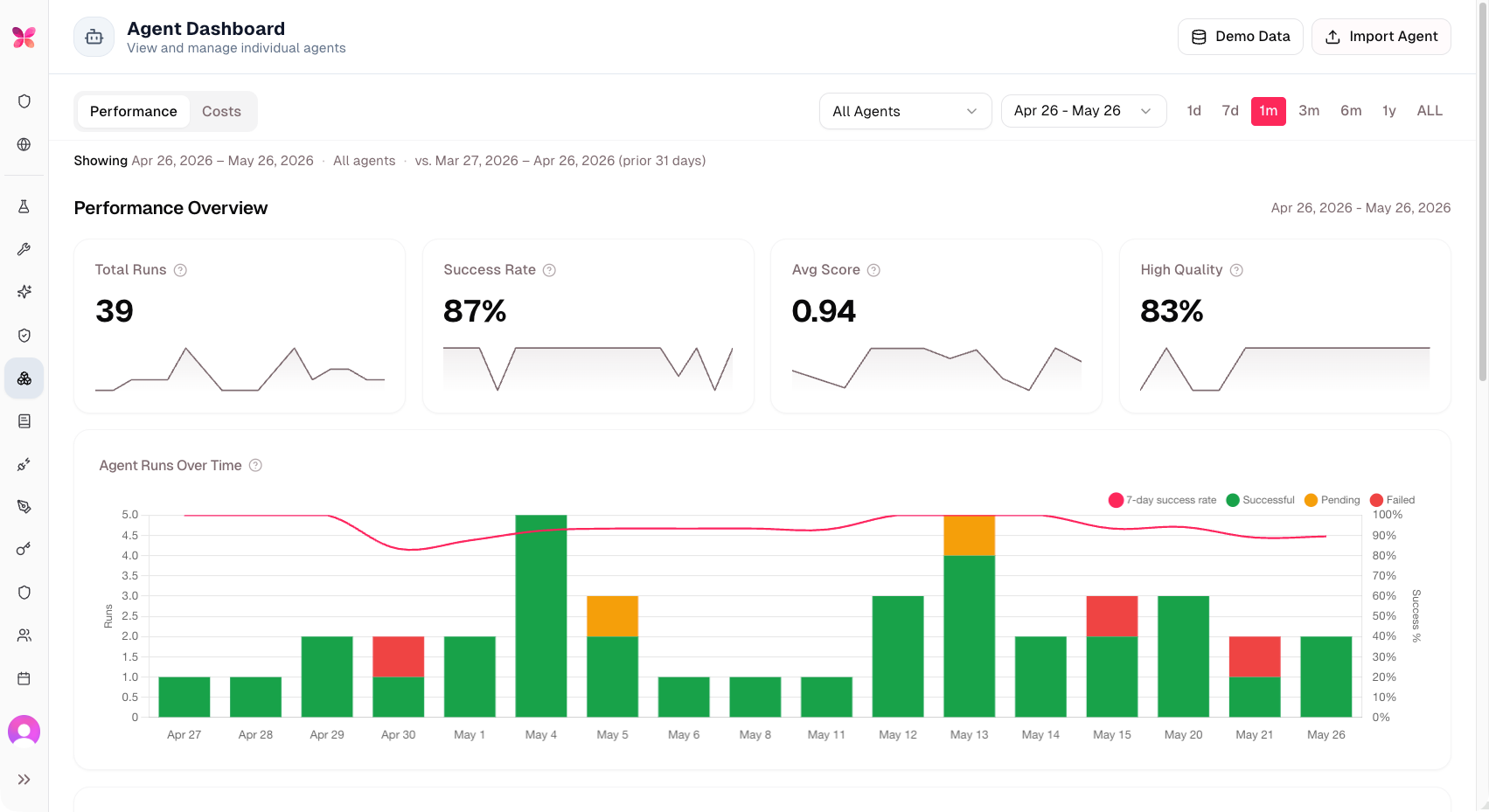
In the early days of AI, companies measured success using soft metrics such as "user engagement" and "customer deflection rates." For autonomous agents, those metrics are useless. Agents are hired to do work—like fully processing an insurance claim, auto-drafting a complex clinical appeal, or managing a supply chain bottleneck.
actAVA v5 re-introduces the Agent Dashboard (formerly "AI Agents"), reimagined and rebuilt around the customer’s AI Agents Directory, complete with a unified agents table, Deployed/Dev/All toggles, search, sortable columns, and a creator column. A new Cost and ROI hero brings cost trends, concentration analysis, and per-agent breakdowns together — including a Top-8 (plus Other) view of agent cost contribution. Date ranges round-trip through the URL, the Cost tab has a proper loading state, and charts include accessibility summaries. A separate SuperAdmin page enables prompt-strategy experiments on ROI calculations. The platform now uses an AgentROIPlan model for ROI tracking; legacy ROI configuration routes are removed.
Smarter, more accessible Tooltips
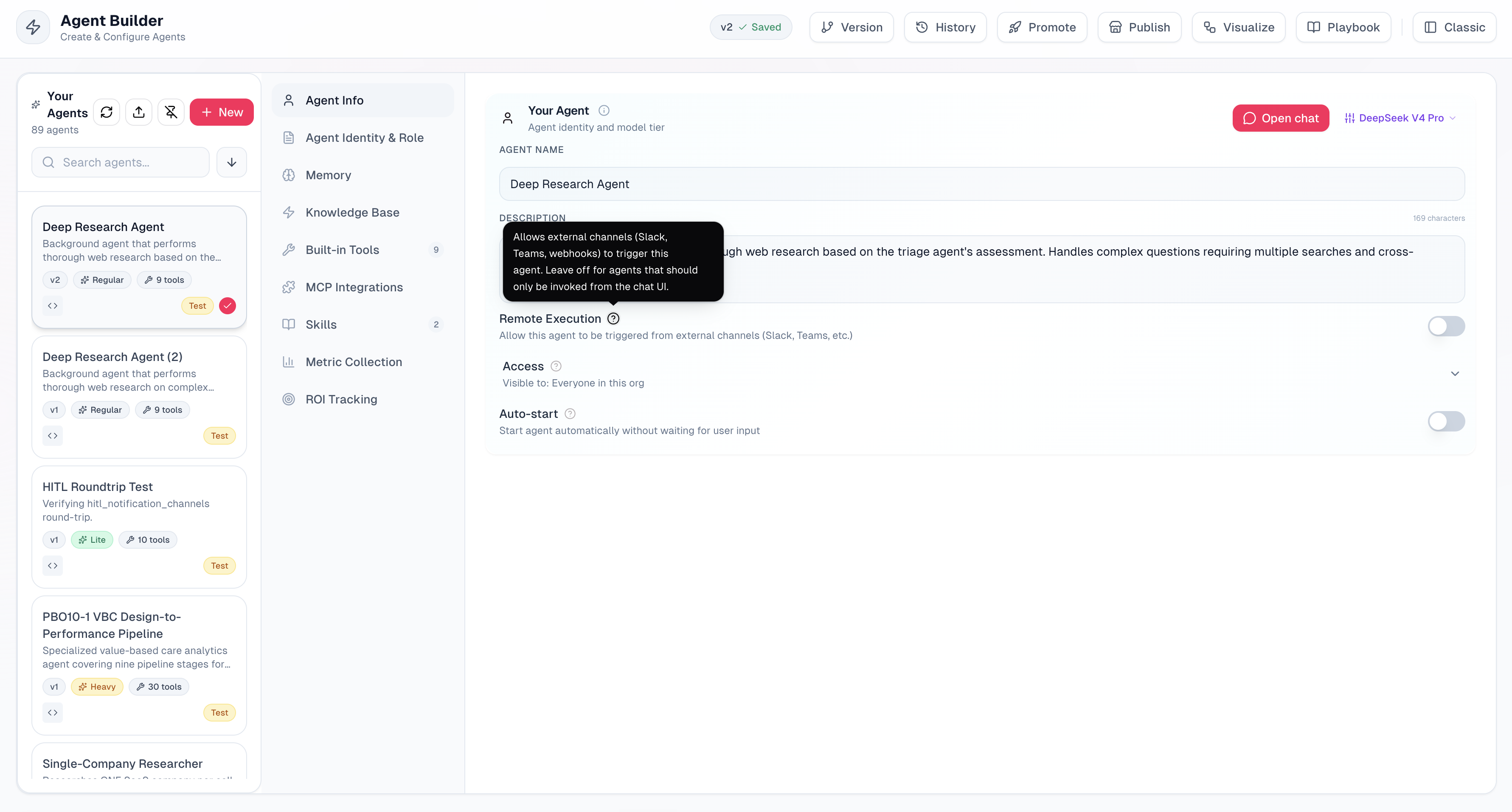
actAVA.ai v5 brings a polished pass over the hover hints throughout actAVA. Across the Agent Builder and admin surfaces, tooltips now do more than label a button — they explain it. Hovering the agent-mode toggle, for example, spells out the difference between building a conversational agent that responds to user messages without a predefined execution plan and a background agent, and the Auto-Generate control clarifies that it will generate agent instructions based on your agent name and description. Contextual help icons (our HelpHint) sit inline next to the settings that need a little extra explanation, so guidance is right where you are instead of buried in docs.
Under the hood, every new icon-only control is built on a single shared component, in which a single label drives both the visible hover tooltip and the accessible name read by screen readers, voice control, and keyboard navigation. The result: tooltips that are one source of truth for the accessible name, fully focus-navigable, and consistent everywhere — part of our broader accessibility-first foundation in this release.
Cortex Runtime Upgrades
actAVA.ai v5 brings powerful upgrades to core agent performance, efficiency, and runtime security. We’ve supercharged the way our AI agents handle complex workflows, large document attachments, and extended conversations. By optimizing worker images, completely overhauling context management, and adding proactive guardrails to tool outputs, v5 ensures your agents operate faster, remain stable over long execution windows, and play nicely with production systems.
Faster cold starts: Document-processing libraries are now baked into the agent worker image, so Word, Excel, and PowerPoint attachments process without download delay.
Long-running agent stability: Context management has been overhauled — evicted content is now summarized in a way the model can still reason over, and cost reporting for long agents no longer double-counts during checkpoint saves.
Secret redaction: Internal environment variables and credentials are stripped from shell-tool output before they reach the model — a defense-in-depth measure for agents running close to production systems.
Agent Builder Improvements
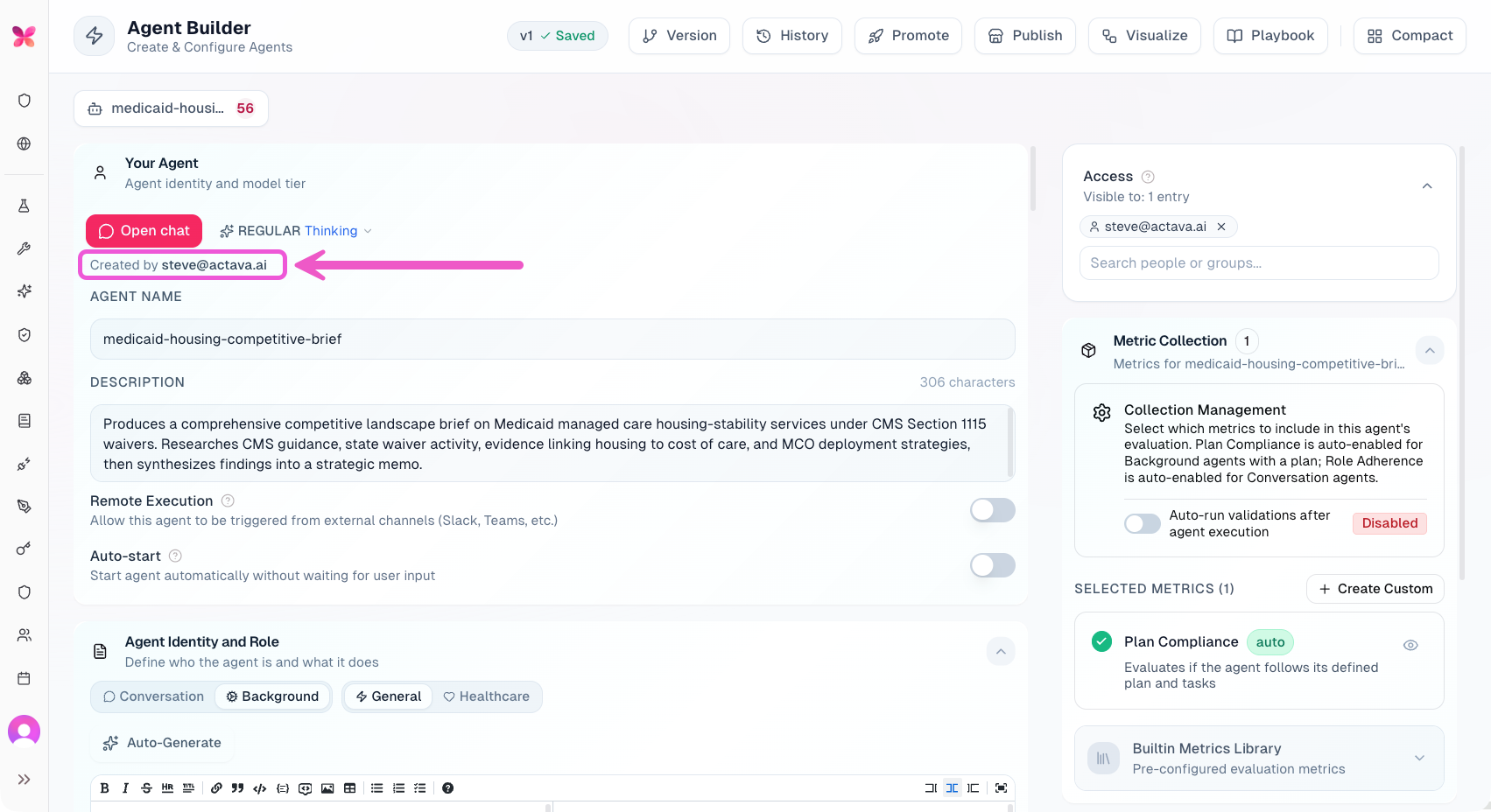
In addition to backend performance and security, actAVA.ai v5 delivers a sweeping set of updates to your daily workspace, collaboration tools, and agent governance. We’ve streamlined how you navigate, manage, and share your workflows—especially for scaling organizations managing large agent portfolios. With tighter default permissions, granular version tracking, and a highly optimized, responsive UI, v5 makes team collaboration both seamless and secure.
Pinned agent list as a left side pane for fast switching across portfolios of agents.
Virtualized agent sidebar for organizations with hundreds of agents.
Least-privilege by default: Newly created agents default to creator-only access (previously organization-wide).
Creator tracking is now stamped on every agent and voice-agent version, and it is surfaced in builder headers, version history, agent listings, and the Agent Directory.
Retroactive format-card defaults for fonts, citations, tables, and margins so existing agents benefit from output-quality improvements without manual reconfiguration.
Workspace deep-linking for sharing a specific run view directly.
Session-aware optimization so improvements derived from a session apply correctly to its workspace type.
Live Monitor now surfaces fan-out workspaces alongside standard runs in a single active-runs view.
Evaluations & Synthesis
Rounding out the v5 release, we’ve completely overhauled our testing and analytics suite to give you unprecedented precision and trust in your agent benchmarks. This update introduces a significantly more sophisticated default evaluation judge, hardens our testing pipeline against transient network blips, and enforces ironclad data isolation between tenants. Whether you're analyzing complex model outputs or stress-testing massive datasets, v5 ensures your evaluation metrics are highly accurate, resilient, and strictly secure.
Evaluation judge upgraded to Claude Opus 4.7 by default for higher-quality grading.
Network reliability: Synthesis and dataset-evaluation calls are now hardened against transient cloud-network issues, with automatic redrive on failed calls rather than permanent failures.
Tenant cross-check enforcement in evaluations and synthesis so that no job can reach across organizational boundaries.
Modernized output extraction from agent traces using the platform's current tracing system.
Longer timeouts for evaluation and long-running model calls in the UI (300 seconds) to accommodate complex grading workloads.
Infrastructure, Security & Accessibility
Reliability
In this update, we’ve tackled the architectural heavy lifting required to keep customer workflows fast, secure, and completely uninterrupted. By focusing heavily on infrastructure resilience, data privacy, and network predictability, v5 eliminates the subtle backend friction points that can disrupt a user’s day. From hardening database failovers against AWS stalls to slimming down our admin bundle for maximum privacy, this version is all about making actAVA.ai leaner, safer, and remarkably more dependable.
Database failover resilience: Connections recover cleanly during AWS Multi-AZ failover events that previously caused multi-minute query stalls.
Cleaner secret rotation through assembled database credentials rather than monolithic connection strings.
Smaller, more private admin bundle: Browser monitoring has been switched to a slim variant with session replay disabled — reducing both bundle size and the surface area of any captured personal information.
Predictable network behavior: IPv4 is now forced across internal service-to-service traffic, eliminating a class of dual-stack-versus-VPC connectivity issues.
Security and Dependency Hygiene
Alongside infrastructure stability, actAVA v5 introduces a heavily reinforced security posture. This update implements rigorous, proactive defenses designed to lock down our ecosystem against emerging threats. By hardening our base images, aggressively patching critical third-party dependencies, and embedding automated vulnerability scanning directly into our core development pipeline, v5 ensures your data remains protected on our most secure foundation yet.
Base image hardening with OS-level package upgrades applied in every production container build.
CVE patches applied across urllib3, axios, Mako, python-multipart, pillow, lxml, litellm, and Clerk's shared library — covering several high-severity advisories disclosed during the release window.
Filesystem vulnerability scanning has been added to every pull request across backend, common, evaluations, routing, and the next-generation platform layer.
Accessibility and Design System
Because a platform is only as powerful as it is inclusive, actAVA.ai v5 features a comprehensive overhaul of compliance and the user experience, with a focus on digital accessibility (a11y). We’ve systematically audited our interface to ensure assistive technologies can navigate our workflows seamlessly and predictably. By baking these standards directly into our codebase through automated lint rules and rigorous testing, v5 eliminates screen-reader clutter. It delivers a first-class user experience across over 15 high-traffic pages.
Accessible names on every icon-only control, enforced by a wrapper component and a frozen accessibility lint rule.
Async surfaces announce their loading state to assistive technologies through a new dedicated lint rule, applied to 15+ high-traffic pages, including Agent Detail, Voice Agent Detail, Knowledge Base, Connectors, Datasets, and Members.
Nine accessibility sweeps covering dialogs, tables, sidebars, pagination, and tooltip-aware buttons.
Test identifier coverage across thirty-six-plus dialogs and tabbed surfaces.
Decorative chrome is hidden from the accessibility tree, so screen readers no longer announce hover-only affordances.
Deprecations & Removals
Projects feature retired (Phase 1) across the backend and admin layers.
Tool-call HITL approval is deprecated in favor of task-level approval.
Agent schedules beta gating removed — the feature is now generally available.
Legacy ROI configuration routes were removed in favor of the new ROI Plan model.
Standalone Voice Runs route retired — runs now live inside the Voice Agent view.
Legacy organization-roles storage retired in favor of canonical roles.
Upgrade Notes
Slack OAuth scope additions — existing Slack installs may need a re-authorization to pick up the new commands and app_mentions: read scopes. Surface this to admins on their next login.
Default model upgrade to Claude Opus 4.7 affects the heavy tier, voice agents, and the evaluation judge. Organizations explicitly pinned to a specific model are unaffected; organizations on defaults will see their behavior shift.
Pricing table changes — rates for Opus 4, Opus 4.1, and Opus 3 have been removed. ROI dashboards referencing those models will show pricing gaps until re-anchored to currently supported models.
/voice-runs route retired — bookmarks redirect into the Voice Agent view; external links may need updating.
"MCP Marketplace" → "MCP Store" rename — internal documentation, customer training materials, and any operational runbooks referencing "Marketplace" should be updated.
Tool-call HITL migration — agents using the legacy approval primitive should migrate to task-level approval before the deprecation window closes.

Written by
Deon Metelski
Chief Product Officer