Blog
Human-in-the-Loop: The Steering Wheel of Healthcare AI
Today, we are looking at where to optimally place Humans-in-the-Loop (HITL) for safe, effective agentic AI deployment. Our founding Forward Engineer, Joon Li, has some thoughts to share on this matter. He works with clients every day, designing ways for agents to become part of the fabric of their work lives.
By Joon Lee
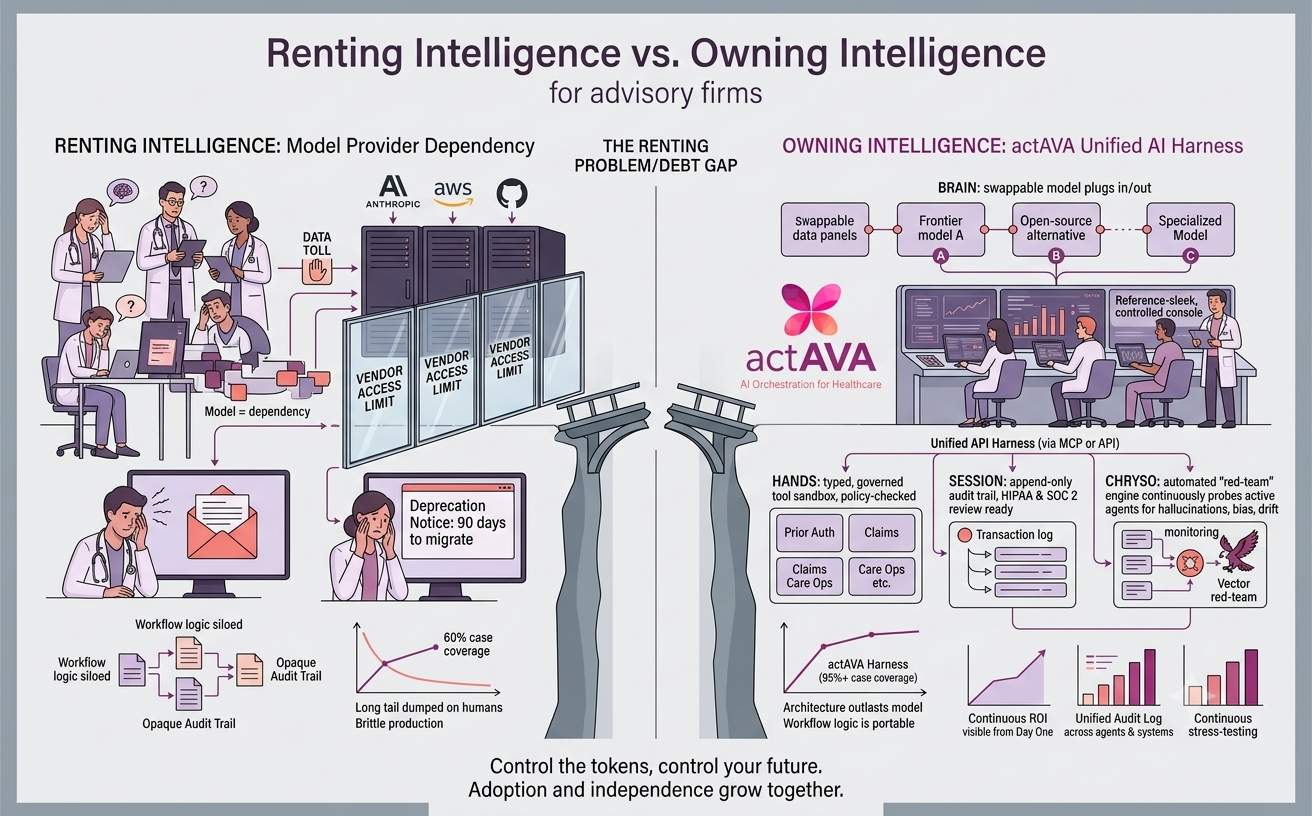
We are officially in the "breakout year" for agentic AI in healthcare. With Large Language Models (LLMs) now hitting human-level performance in medical reasoning, the conversation has shifted. There is no doubt that AI delivers real value to healthcare & life sciences. AI agents have evolved from passive tools into autonomous digital coworkers capable of planning, reasoning, & executing complex tasks independently. It’s no longer a question of if we should use AI, but how we integrate the most important component of the system: the human.

According to McKinsey's 2025 analysis, we should expect to see notable incremental value from the use of agents, as shown in part in the metrics in the image above.
The stakes couldn't be higher. While AI alone shows a respectable 92% diagnostic accuracy, adding a Human-in-the-Loop (HITL) pushes that number to a staggering 99.5%. Beyond performance, human oversight is now a regulatory mandate under frameworks like the EU AI Act.
The Three Pillars of Healthcare HITL
Strategic placement of human judgment isn't a one-and-done task. It must be woven into three distinct phases of the AI lifecycle.
Model Development: Building the Foundation
Workflow Development: Putting it Into Action
Continuous Improvement: The Feedback Loop
1. Model Development: Building the Foundation
Human involvement in the development of language models, whether large-scale or more specialized, small models, is not merely beneficial—it is absolutely mandatory and critical from the project's inception. The fundamental success and reliability of any language model hinge entirely on the quality and representativeness of the data upon which it is trained. Without meticulous human oversight and intervention from "day one," there is a substantial risk that the resulting models will be built on flawed, biased, or unrepresentative data sets.
This Human-in-the-Loop (HITL) approach ensures that data curation, labeling, and validation processes are guided by human understanding, domain expertise, and an ethical framework. In essence, mandating human involvement ensures that the linguistic and conceptual foundations of the models are sound, ethical, and fit for purpose, transforming raw data into a reliable, high-quality, and trustworthy resource. This direct involvement is necessary to:
Ensure Data Quality: Humans are essential for scrubbing data, identifying and correcting factual errors, and removing low-quality, ambiguous, or irrelevant examples that would otherwise pollute the training set.
Mitigate and Address Bias: Training data often reflects real-world societal biases. Human annotators and reviewers are the primary defense against embedding these biases into the model, identifying unrepresentative demographics, unfair language, or discriminatory patterns, and actively balancing the data or applying necessary safeguards.
Establish True Representation: To perform effectively in diverse, real-world scenarios, a model must be trained on data that accurately reflects the context, dialects, and nuances of its intended use. Human experts guide the collection and annotation of data to ensure this essential breadth and representativeness, moving beyond easily accessible, but often skewed, internet data.
Validate Model Outputs: Even after initial training, continuous human evaluation is required to fine-tune the model, assess its coherence and factual accuracy, and verify that its outputs align with the desired ethical and performance standards before and after deployment.
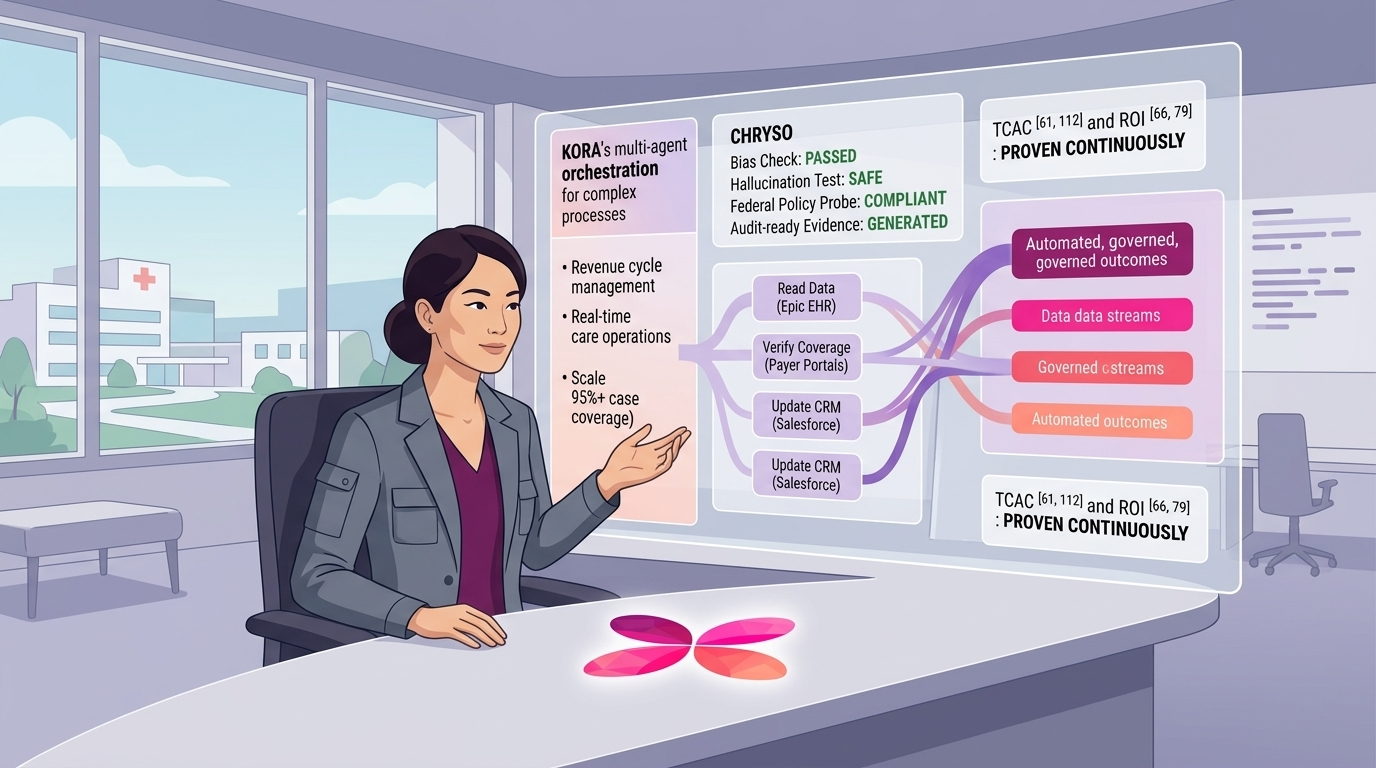
Healthcare organizations use tools like actAVA’s KORA|RED agent testing + remediation suite to test models in real-world scenarios before they go live.
2. Workflow Development: Putting it Into Action
In the complex landscape of multi-agent systems and advanced automation, the integration of human oversight—often termed Human-in-the-Loop (HITL)—represents the critical juncture where algorithmic efficiency meets real-world accountability. Here, the "rubber meets the road." Specifically, within sophisticated, multi-agent pipelines designed to handle nuanced tasks (such as human care transactions, clinical document generation, or sensitive customer service interactions), humans act as the final sign-off.
This final sign-off is not merely a formality; it is a vital safeguard that injects ethical review, domain expertise, and common-sense reasoning into the automated workflow. Before a definitive action is taken, be it executing a transaction, sending a pivotal communication, or committing to a legally binding decision, the system flags the output for human review. HITL ensures that the cumulative decisions of preceding AI agents are validated against human judgment, particularly in edge cases, high-stakes scenarios, or when the system's confidence score falls below a predetermined threshold.
The human role is, therefore, one of ultimate responsibility and quality control, bridging the gap between theoretical AI capabilities and practical, safe deployment. In short, humans intervene in strategic parts of the workflow where agents did the heavy lifting and handle validation.
Here is an example of a clinical workflow in which humans and AI work in concert.
Sourcing: A scribe agent takes notes, a coding agent assigns codes, and a prior authorization agent prepares documents—but a human review must sign off on the final output.
Safety: In systems like actAVA, agents can draft the “next step” and self-check their work before presenting it to humans for approval with a single, informed click.
Escalation: AI agents can then return to work and handle follow-up activities, such as post-discharge follow-ups, while still allowing escalation to a human when a patient shows concerning symptoms.
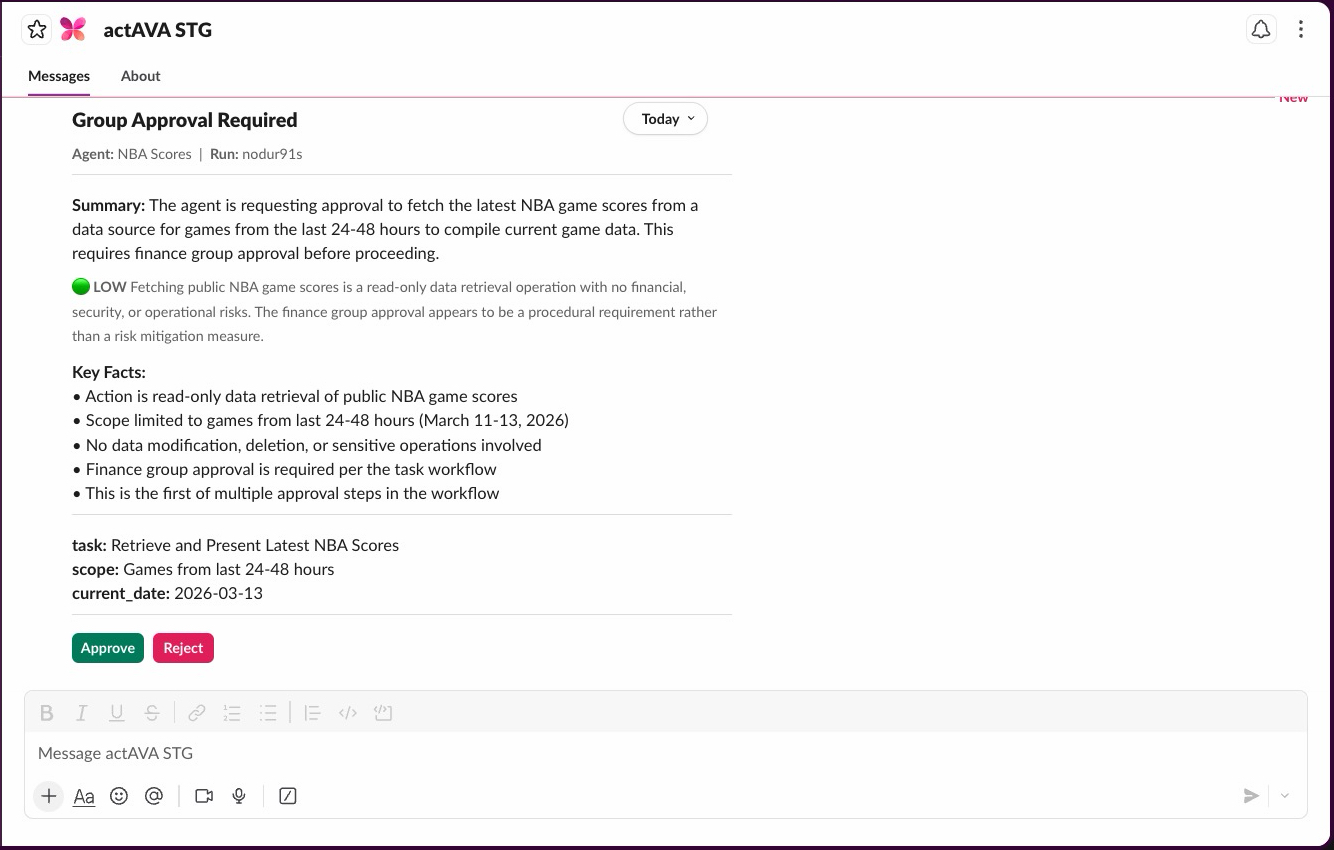
Healthcare organizations use tools such as actAVA’s KORA|BLUE agent building + orchestration suite to ensure agentic workflows have a human-in-the-loop where appropriate.
3. Continuous Improvement: The Feedback Loop
The act of deploying an agent is often mistakenly viewed as the culmination of the development process. In reality, it is merely the point of transition, a launchpad for continuous improvement. The moment the agent encounters the real world, it begins generating invaluable, high-fidelity data that no simulated or staging environment could replicate. And because it is AI, it also drifts and hallucinates.
For an organization, viewing deployment as the beginning of this cycle transforms the investment from a one-time project cost into an ongoing strategic asset. It necessitates a commitment to robust monitoring infrastructure, a culture of rapid iteration, and the establishment of clear agent MLOps and DevSecOps pipelines to facilitate swift, safe, and continuous evolution.
This live environment initiates the Cycle of Continuous Improvement, which is defined by three inseparable phases:
Prediction: The deployed system begins making real-world inferences and predictions. This phase validates the model's performance on live data and under actual operational constraints, exposing nuances, biases, and edge cases that were previously hidden. It also estimates the cost per run for each agent and compares it to an ROI-AI (return on investment per agent).
Feedback: The performance of these real-world predictions is rigorously monitored. Telemetry, user feedback, and A/B testing provide the critical signal necessary to identify where the system is failing, succeeding, or exhibiting drift. This feedback loop informs necessary adjustments, whether they are minor parameter tweaks, data pipeline modifications, or significant architectural overhauls.
Learning: This is the most critical and often overlooked phase. The insights gathered from the correction phase are not just used to patch the current system; they are internalized to fundamentally improve the next generation of the system and, more importantly, the processes that build it. This learning drives the creation of new features, refines training data hygiene, improves data labeling strategies, and enhances the robustness of monitoring and alert systems.
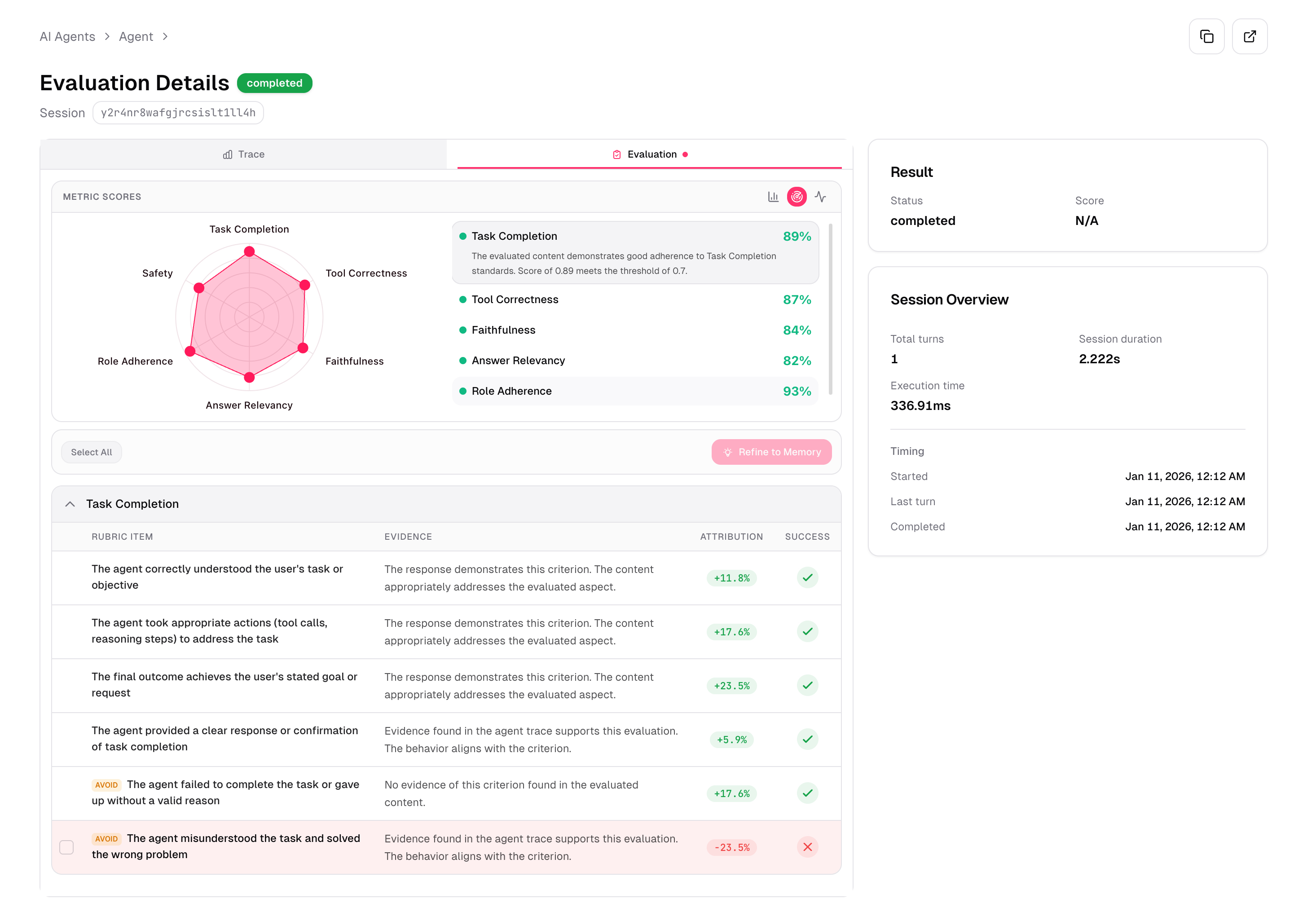
Healthcare organizations use tools such as actAVA’s KORA|GREEN agent continual learning suite to ensure agentic workflows learn from their mistakes, perform at optimal levels, and operate at the lowest cost per run.
actAVA HITL Approval Groups
actAVA has a special set of features designed for HITL approval groups. These are powerful organizational tools that centralize and standardize your approval processes. Rather than navigating scattered email chains and unclear sign-off requirements, these groups create a unified framework where critical decisions receive the right level of human review and authorization every time.
By integrating human oversight at both the tool level and task level, HITL approval groups ensure that human judgment guides your processes at every critical juncture—whether approving specific tool executions or validating entire task workflows. This multi-layered approach to human-in-the-loop governance provides comprehensive control and accountability across your entire operation.
Flexible Approval Policies: Choose the approval method that works best for your organization. Whether you need a single member to approve, require unanimous consensus, or prefer majority rule, HITL groups adapt to your governance needs.
Configurable Requirements: Set minimum approval thresholds, establish response timeouts for automatic rejection, and define exactly how many stakeholders must weigh in. You're in control of the rules.
Clear Accountability: With named groups and defined member roles, everyone knows who's responsible for what. Transparency builds trust and accelerates decision-making.
Scalable Workflows: From clinical review boards to compliance committees to executive sign-offs, HITL groups handle approval workflows of any complexity. Grow your organization without growing your administrative burden.
Multi-Level Human Oversight: Control approvals at both the tool level and task level, ensuring human judgment is applied exactly where it matters most. Whether validating individual tool executions or entire task sequences, you maintain complete visibility and authority over your operations.
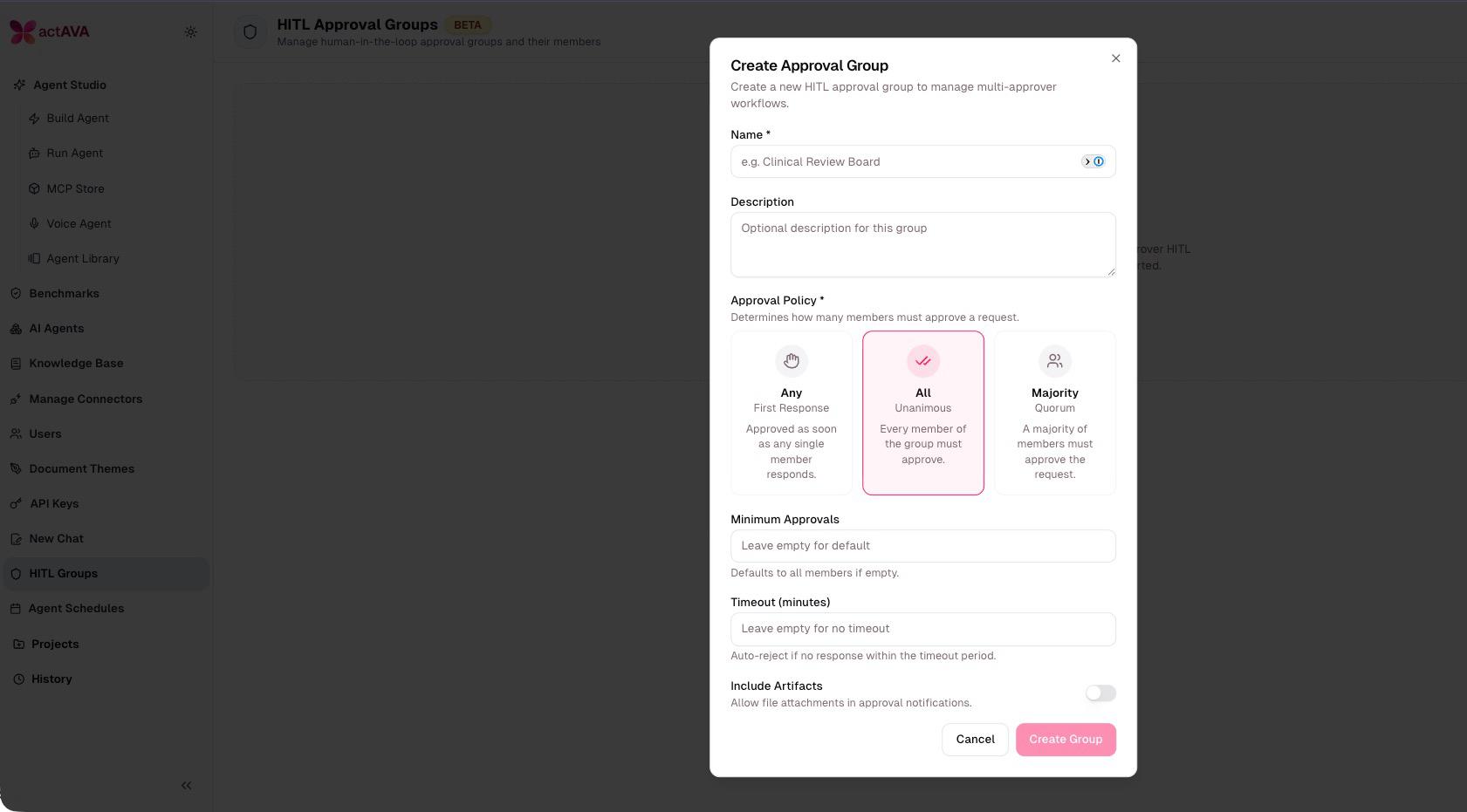
The HITL Design Checklist
Before deploying any healthcare AI agent, run through this checklist to ensure your "loop" isn't just a hollow checkbox:
[ ] What exactly is the person expected to do at the decision point?
[ ] Do they have enough time to make an informed decision?
[ ] Are all necessary constraints and information visible to the human?
[ ] Is there a clear, practical way to override the AI?
[ ] Is there a defined escalation path if the human disagrees?
[ ] Are all decisions logged with clear accountability for audits?
Red Flags: If your HITL is "just a click," lacks a clear decision owner, or provides no visibility into why the AI made a recommendation, you aren't designing for safety—you're designing for a disaster.
By strategically placing humans in the loop, organizations don't just mitigate risk—they unlock the full potential of AI. Humans at critical decision points ensure safety, while continuous feedback loops keep the technology aligned with clinical reality.
AI is the engine, but humans must remain at the steering wheel.

Written by
Joon Lee
Lead Forward Deploy Engineer