Blog
Meet Haolin Chen
We took this Friday to interview Haolin Chen, Lead AI Researcher at actAVA.ai, on the concept of agentic AI, evaluation, and what it takes to make AI actually work inside real enterprise workflows.
Haolin Chen is the Lead AI Researcher at actAVA.ai, where he spearheads the development of cutting-edge agentic systems and reinforcement learning (RL) frameworks. Previously a Senior Applied Scientist at Salesforce AI Research, Haolin led high-impact projects including LaTRO (foundational RL-based reasoning), Webscale-RL for massive-scale data synthesis, and the xLAM series of agentic LLMs. His technical expertise spans the entire LLM lifecycle—from pre-training to hierarchical planning—and includes the development of CoDA, a diffusion language model for coding. A prolific researcher with 15+ publications in venues like NeurIPS and ICLR, Haolin holds a PhD in Applied Mathematics from UC Davis, specializing in the mathematical foundations of machine learning and tensor decomposition.
When people hear “agentic AI,” it can sound abstract. What does it actually mean in real workflows?
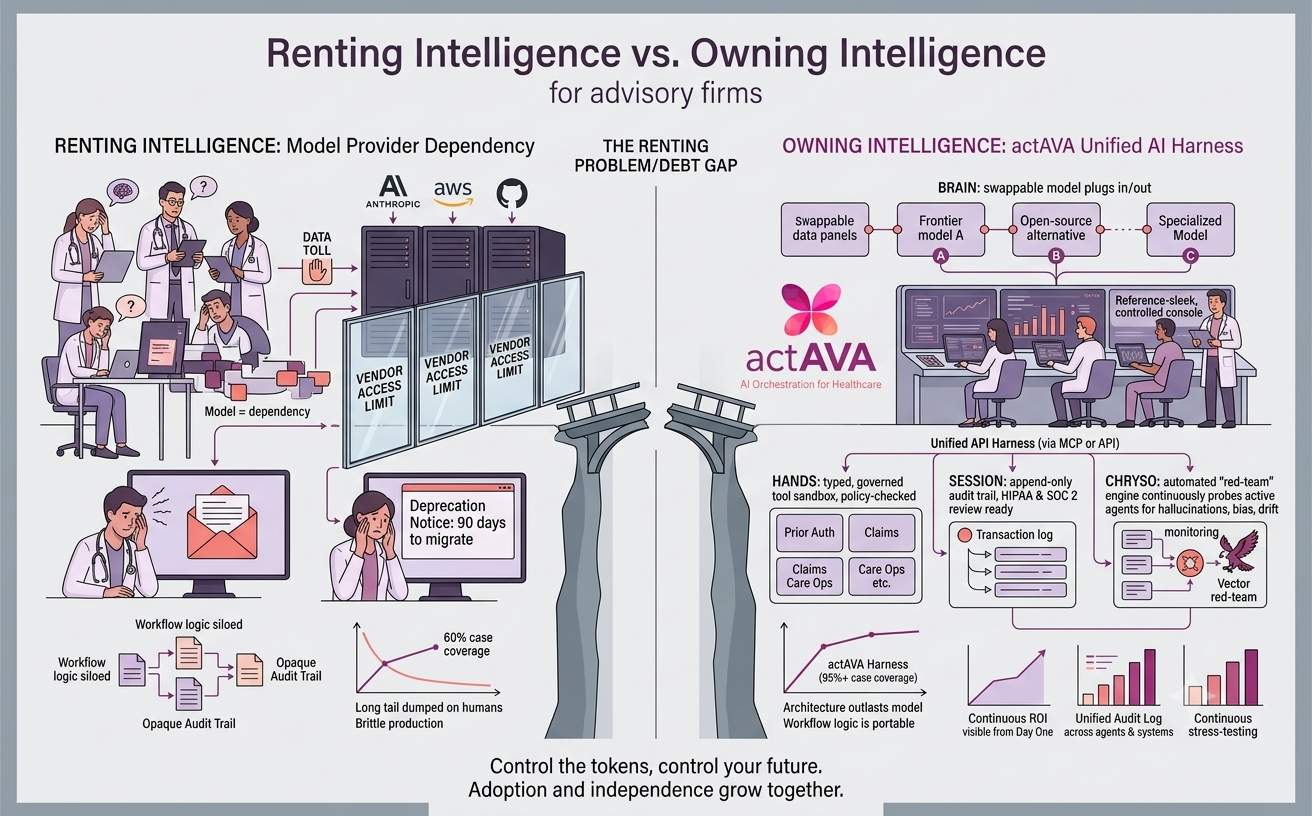
At a practical level, agentic AI means moving beyond a chatbot that simply answers questions. An agent is a system that can understand a goal, gather the right information, make intermediate decisions, use tools, and help complete a multi-step task.
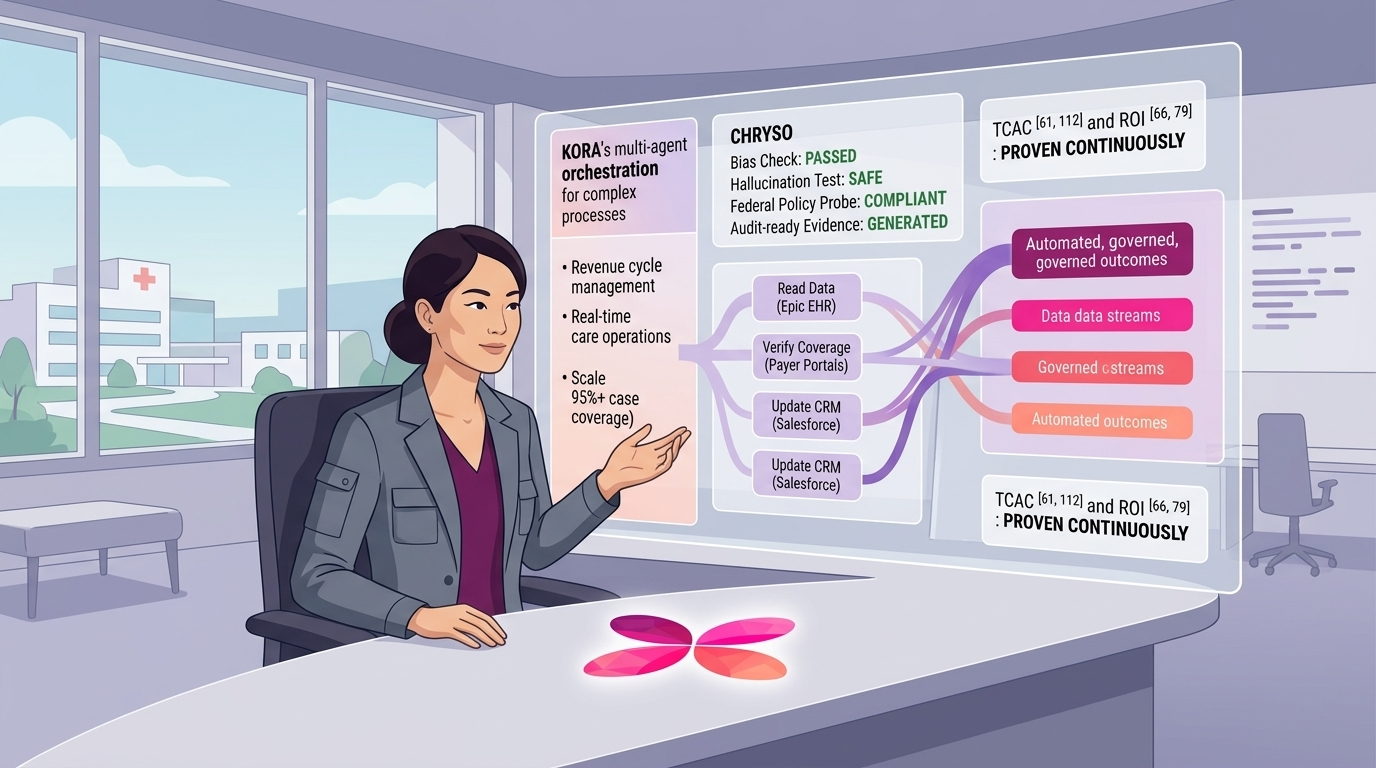
That matters because most enterprise work is not a single prompt-and-response. In healthcare, a prior authorization case may require reviewing clinical notes, checking policy criteria, identifying missing evidence, and deciding whether to submit, escalate, or request more information. In care operations, a workflow may involve patient outreach, follow-up scheduling, risk monitoring, and exception handling. In life sciences, it may mean synthesizing evidence across internal documents, external research, and operational processes before recommending a next step.
The same pattern also appears outside healthcare. In insurance, it can look like claims review and exception routing. In financial services, it may involve compliance checks, underwriting support, or investigation workflows. In each case, the real value comes from helping people move work forward—not just generating text, but supporting a decision process from beginning to end.
You often talk about “benchmarks” and “environments.” What is the difference, and why does it matter?
A benchmark is like an exam: it tells you whether the system got the answer right.
An environment is closer to the world in which the system operates. It defines what the agent can see, which tools it can use, what actions it can take, and what feedback it receives as it progresses through a task.
That difference matters because real workflows are interactive. In healthcare, an agent may need to review incomplete information, select the appropriate retrieval step, determine whether the evidence is sufficient, and escalate when confidence is low. If you only measure the final answer, you may miss whether the system got there in a safe, reliable, and traceable way.
For enterprise AI, that is a major distinction. A system might look impressive in a simple benchmark but still struggle in production when it faces ambiguity, missing context, policy constraints, or multiple systems. Good environments let you test the full workflow, not just the last sentence.
What does a good benchmark or environment look like for healthcare and other enterprise workflows?
A good benchmark should feel less like a trivia quiz and more like a realistic job simulation.
First, it should reflect the actual structure of work: multi-step tasks, incomplete information, tool use, branching decisions, and clear outcomes. Second, it should measure more than just accuracy. In healthcare, especially, you also care about safety, evidence quality, consistency, escalation behavior, latency, cost, and compliance. Third, it should include a range of difficulty, from routine cases to ambiguous or edge-case scenarios.
For example, in healthcare, you may want to evaluate whether an agent can correctly navigate a prior authorization workflow, summarize clinical evidence for a reviewer, support post-discharge follow-up, or surface the right coverage intelligence for an operations team. In other industries, that might translate to claims operations, fraud review, customer case resolution, or policy-driven document handling. The underlying pattern is similar: the system must operate within a process, not just answer a question.
To me, the best environments are the ones where practitioners immediately recognize them as realistic. If an operations leader, clinician, payer team, or enterprise buyer looks at the task and says, “Yes, this is close to the work we actually do,” then you are much closer to building something useful.
Bonus Round: Why is reinforcement learning important for enterprise AI, especially in healthcare?
Reinforcement learning matters because many enterprise workflows are not judged by a single response—they are judged by the quality of a sequence of decisions.
A model might produce a fluent answer, but that does not mean it chose the right next step, used the right tool, gathered the right evidence, or handled uncertainty correctly. Reinforcement learning gives us a way to improve those behaviors over time. Instead of only asking whether the output sounds good, we can optimize for whether the agent completes the workflow successfully, safely, efficiently, and consistently.
That is especially important in healthcare. In workflows such as prior authorization, patient engagement, utilization management, or evidence review, a single poor decision early in the process can lead to downstream delays, denials, increased operational costs, or compliance risks. Reinforcement learning helps shift the focus from “Did the model say something plausible?” to “Did the agent behave well across the whole workflow?”
For enterprises more broadly, this is a big unlock. It means AI systems can become more adaptable rather than remaining frozen after deployment. They can learn from feedback, improve their operational practices, and become more aligned with business outcomes over time. In healthcare, that improvement has to happen with strong guardrails, transparency, and human oversight—but when done correctly, it creates AI systems that are not only powerful, but genuinely dependable in day-to-day operations.
That is where I think the future is headed: not just smarter models, but better-behaving systems that can operate within real workflows and keep improving.
Thanks for the time today, Haolin, and for helping us understand how agentic AI, evaluation environments, and reinforcement learning are shaping the future of healthcare and enterprise workflows.
Visit us at https://actava.ai/ to learn more.
Meet Haolin: View LinkedIn Profile