Blog
Meet Weiran Yao
We took this Friday to interview Weiran on the concept of red-teaming in AI, how it works, and why healthcare and life sciences companies cannot do without it.
Meet Weiran Yao, CAIO and co-founder of actAVA.ai
Werian Yao is an AI research leader with deep expertise in large-scale model training, reasoning engines, and multi-agent systems. Weiran led Salesforce AI Research's development of the Agentforce planning engine, CodeGenie agent, and Large Action Model (RL/SFT) pipelines, and recently spearheaded open-source releases including Enterprise Deep Research (EDR), Webscale-RL, and CoDA-1.7B. He holds a Ph.D. in Machine Learning from CMU and has published more than 85 papers on AI. He also holds 13 U.S. patents and serves as an area chair on the program committees for NeurIPS, ICML, ICLR, and ACL.

We took this Friday to interview Weiran on the concept of red-teaming in AI, how it works, and why healthcare and life sciences companies cannot do without it.
Dr. Yao, you often use the term red-teaming when you refer to testing AI for healthcare - what exactly do you mean?
Red teaming is a testing discipline borrowed from traditional software: a “red team” actively tries to break a system, and a “blue team” fixes what it finds. In AI, it originally meant probing models for safety failures—people crafting prompts to trigger harmful or noncompliant behavior, then developers addressing those issues through training and mitigations.
Today, red teaming has expanded beyond pure safety into broader agent evaluation: stress-testing an AI agent’s end-to-end behavior (plans, tool use, decisions, and outcomes). To make red teaming work for AI agents, you need (1) strong data synthesis pipelines—often with human annotation—to uncover realistic failure modes, (2) robust evaluation systems that score agent trajectories against human-labeled ground truth or human-written rubrics, and (3) a remediation loop that turns findings into concrete fixes.
Why is actAVA’s Platform so focused on Red-Teaming, and how?
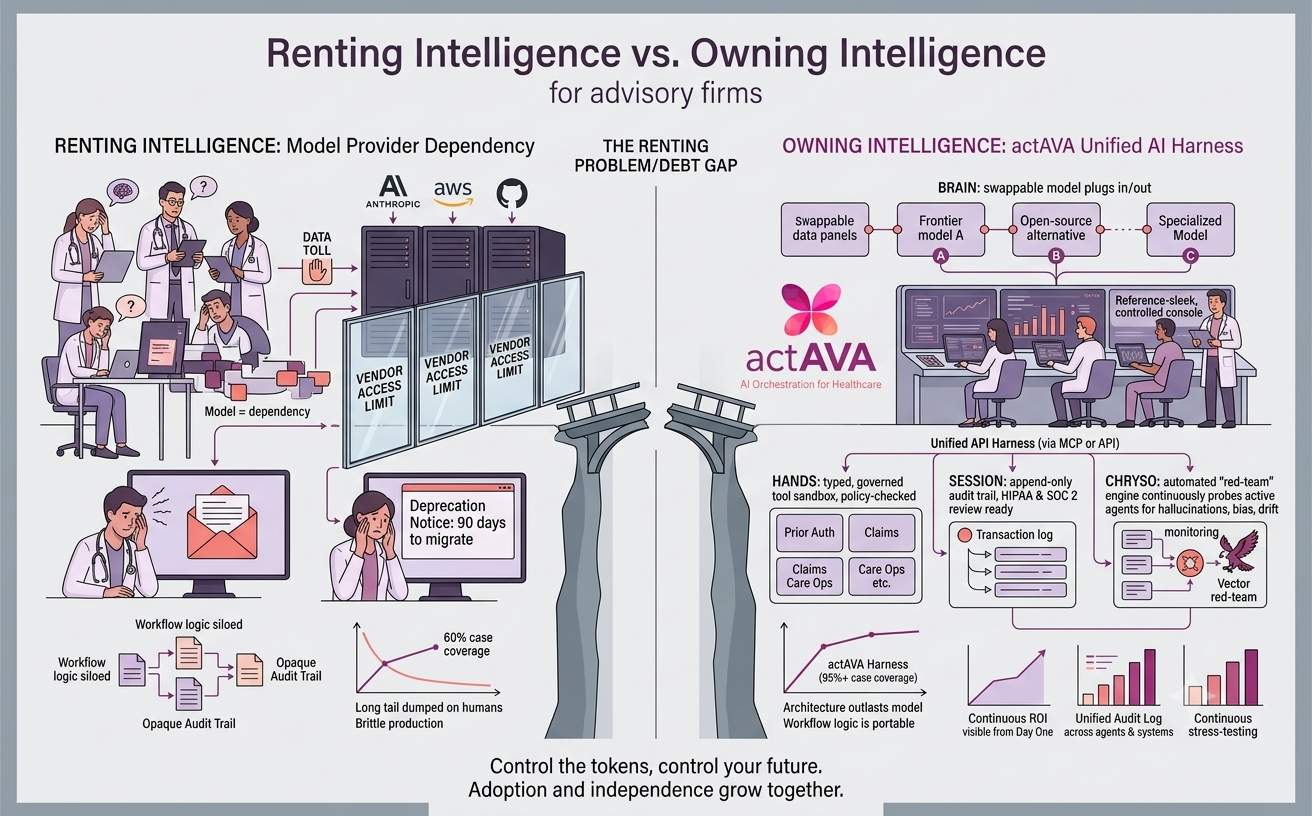
In healthcare, safety and accuracy aren’t “nice to have”; they’re foundational. actAVA is built as a three-part loop—a data flywheel, and Red-Teaming is one crucial component of the loop:
actAVA Blue: Here, we build advanced AI agents and plug them directly into customers’ real healthcare workflows. As agents work, we collect high-quality data from daily operations.
actAVA Red: Here, we evaluate full agent trajectories against customer-defined success criteria. This is really red teaming in the broader sense of “agent evals.” We also synthesize targeted test data based on the agent configuration, tool selection, workflow structure, and success criteria, so we can proactively uncover failure modes before the agent encounters them in production.
actAVA Green: Here, we use evaluation and red-teaming data, especially customer feedback, to inform our AI data flywheel. We use it to continuously optimize the system (including reinforcement learning / continued learning), driving it toward self-improvement over time.
We focus so much on red teaming because the cost of error in healthcare is fundamentally different: one mistake in a thousand might be tolerable for a coding agent, but it can be unacceptable in clinical and regulated workflows.
Why is this type of testing so important for your customers?
Healthcare and life sciences operate in a regulated environment where workflows are explicit and well-documented: which steps must be followed, what evidence must be collected, and when human approval is required. Customers’ biggest question isn’t “can the agent be clever,” it’s: Is the agent compliant, and does it do exactly what the workflow requires—every time?
Unlike domains where exploration is encouraged (e.g., coding agents, creative generation), healthcare workflows demand precision, traceability, and zero tolerance for safety issues. Red teaming/agent evaluation helps customers gain confidence that an agent follows regulated steps with 100% accuracy, produces the right evidence, respects required human-in-the-loop gates, and avoids unsafe behavior.
Bonus Round: What is your prediction for the biggest AI trend impacting your customers in 2026?
Two trends will shape 2026 for regulated industries like Healthcare and Life Sciences:
More capable models → more powerful agents: model capability is improving quarter by quarter, and agents will take over more real operational work—operating file systems, terminals, browsers, and increasingly connecting to enterprise and vertical data sources. As agents interact with more systems of record, the need for accuracy and instruction compliance becomes even more critical.
Rising regulation and public scrutiny → demand for evidence: governments (federal and state) are moving toward stronger AI security and compliance regulations, including for agentic systems. Many enterprises still underestimate this shift and don’t proactively test agents or produce evidence for AI compliance. As awareness grows, customers will prioritize tooling that continuously validates compliance and generates auditable evidence—driving the industry toward more rigorous evaluation, monitoring, and safety-by-design.
As AI becomes more operationally powerful, it will also be under increasing scrutiny—making continuous red teaming, compliance evaluation, and evidence generation core requirements for healthcare AI deployments.
Thanks for the time today, Weiran, and for your vision for AI safety that we should all strive to achieve.
Visit us at https://actava.ai/ to learn more.
Meet Weiran: View LinkedIn Profile