Blog
The 5 Dimensions of Safe Healthcare AI Deployment
Dr. Weiran Yao, Chief AI Officer at actAVA and a leading researcher on the new actAVA χ-BENCH, walks us through the 5 Dimensions of Safe Healthcare AI Deployment. Traditional artificial intelligence evaluations predominantly rely on static benchmarks that measure isolated accuracy—essentially treating complex operational tasks as closed-book knowledge examinations. In highly regulated healthcare environments, workflows such as prior authorization (PA), utilization management (UM), and care management are fundamentally transactional, policy-dense, and multi-layered. Consequently, high performance on standard multiple-choice leaderboards fails to guarantee production readiness. True operational resilience can only be verified by exposing AI agents to dynamic, multi-step environments where vulnerabilities extend far beyond linguistic fluency or factual correctness. Read to find out more.
By Weiran Yao
The 7 Ways Healthcare Agents Fail Before You Deploy Them
Most healthcare AI evaluations test accuracy. They give the agent a clinical question, check the answer, and report a score. That is not a production readiness test. It is a knowledge quiz. Prior authorization, utilization management, and care management are not knowledge quizzes — they are multi-step, policy-dense, multi-role transactions that fail in ways that knowledge scores will never capture.
Here are the seven failure modes that actually matter — and that a production readiness evaluation must surface before an agent touches real work.
Reasoning Failures
The agent applies the right policy to the wrong clinical fact, or the right clinical fact to the wrong policy. It reaches a plausible-sounding conclusion that is clinically or administratively incorrect. This failure mode is invisible in accuracy benchmarks because the model is confident and fluent, yet wrong in a way that looks right to a reviewer who does not already know the answer.
Policy Interpretation Failures
Every payer is different. Every plan is different. Every state has its own overlay. An agent that passes a generic UM benchmark can still misread a plan-specific formulary exception, misapply a MHPAEA parity requirement, or miss a step therapy criterion that is buried in a 47-page clinical policy bulletin. Policy interpretation failures are the most common source of wrongful denials — and they are exactly what χ-Bench's 1,279-document policy handbook is designed to surface.
Handoff Failures
Real healthcare workflows cross organizational and system boundaries. A prior authorization begins on the provider side and is completed on the payer side. Case management hands off between care settings. In our χ-Bench testing, the provider-payer handoff resulted in 0% completion across every model-agent combination tested. Handoff failures are the hardest to catch in isolated agent tests and the most consequential in production.
Tool Use Failures
An agent may know what to do and still call the wrong tool, call the right tool in the wrong sequence, pass malformed inputs, or fail to handle an unexpected tool response. In a 200-tool production environment — EHR lookups, eligibility checks, document generation, FHIR submissions — tool-use failures are common. They often do not surface in demo environments where the happy path is pre-scripted, and tool responses are simulated.
Documentation Failures
Healthcare agents must produce outputs that meet regulatory and clinical documentation standards — not just correct outputs, but correctly formatted, correctly attributed, and correctly structured outputs that will pass audit. An agent that generates a technically correct prior authorization decision in a format that does not satisfy CMS-0057-F requirements has not completed the task. Documentation failures are invisible in accuracy scores and catastrophic in compliance audits.
Escalation Failures
The most dangerous agent does not know when to stop. A behavioral health prior authorization denial must route to a qualified BH clinician — it cannot be decided autonomously. A member with a crisis-flagged HRA must trigger a human response within 48 hours. Escalation failures occur when agents complete tasks they should have escalated or escalate tasks they should have completed. Neither failure mode shows up on a leaderboard that only counts completions.
Consistency Failures
Run the same case twice and get two different answers. In our χ-Bench testing, no agent exceeded 8% in consistency testing — meaning even the cases agents "pass" are not reliably repeatable. For a healthcare operation processing thousands of similar cases, an inconsistent agent is not an agent you can operate with. It is a liability with variable output.
Why Your Healthcare Agent Needs Workflow Simulation — Not a Demo Script
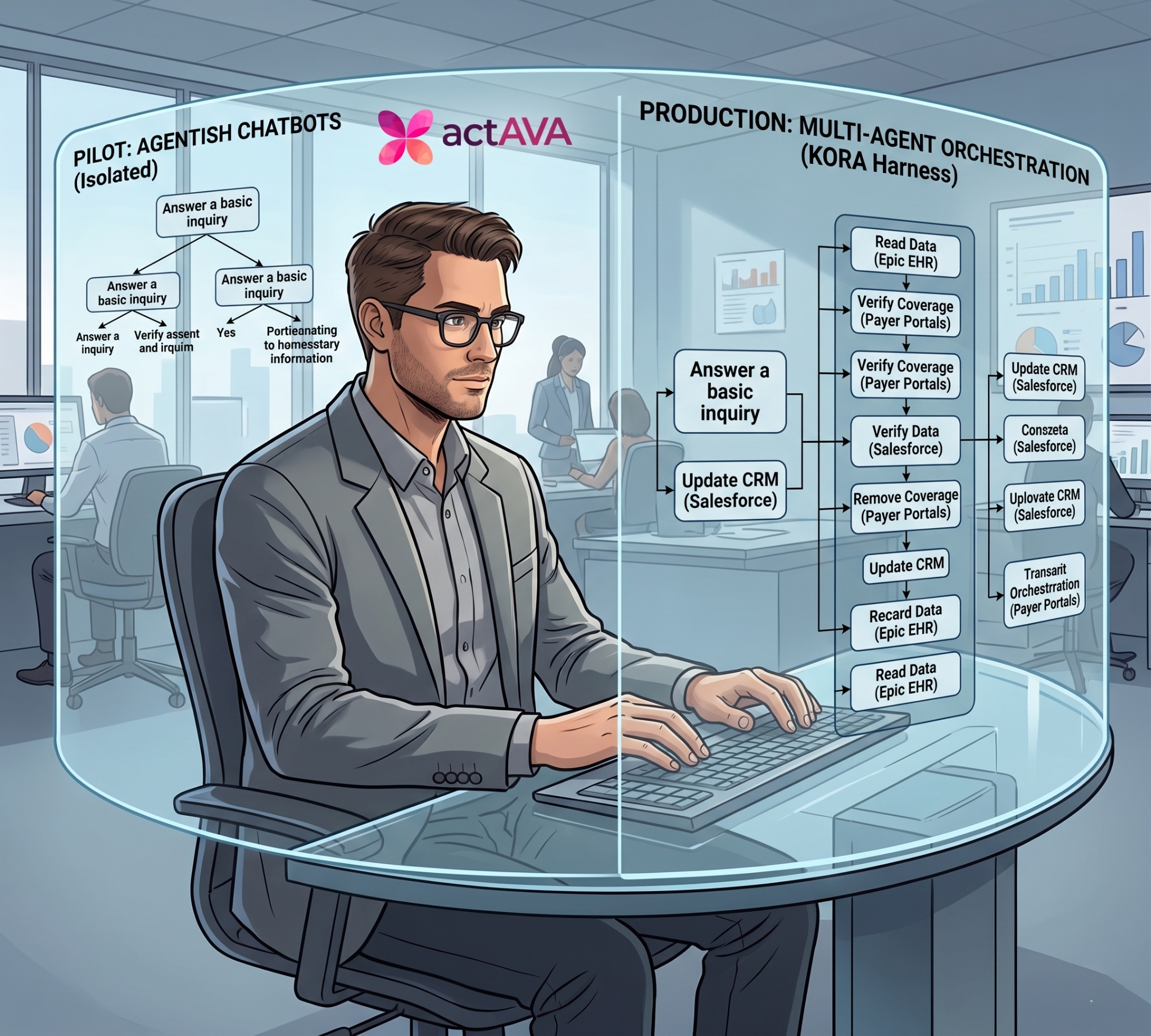
There is a fundamental difference between a demo script and a workflow simulation. A demo script shows you the best case. A workflow simulation shows you what happens when the case deviates from the best path — which is exactly what real healthcare operations do, all day, every day.
Prior authorization edge cases are not exotic. They are routine—a member with dual coverage and a complex behavioral health history. A prior authorization submission that arrives after the authorization window has closed. A utilization management review where the clinical documentation contradicts the diagnosis code. A plan-specific formulary exception that requires a step therapy attestation that the EHR does not support.
These are the cases that make up the long tail of healthcare administration — the 40% that graph-based automation fails on and hands back to humans. A workflow simulation systematically recreates them using synthetic patients and real policies before an agent is deployed.
What Demo Scripts Test
- The happy path, pre-scripted
- Vendor-selected cases the agent passes
- Single-step or shallow tool interactions
- Simulated system responses, not live integrations
- Performance in a controlled, favorable environment
What Workflow Simulation Tests
- Edge cases drawn from real administrative variation
- Policy-dense, multi-step, multi-role transactions
- State that persists across 60–80 tool calls
- Handoff scenarios between provider and payer
- Consistency — does the agent pass the same case twice?
χ-Bench's simulation environment — 21 healthcare apps, 200+ MCP tools, and a 1,279-document managed-care operations handbook — was built specifically to recreate the conditions that distinguish production from demo. The benchmark is open-sourced, so any organization can run its agents against the same cases using its own model configurations before committing to a production deployment.
What Every Payer Should Ask Before Buying a Healthcare AI Agent
Right now, every healthcare AI vendor is claiming production readiness. Same demo. Same pitch deck. Same promise: "our agents handle prior authorization end-to-end." Procurement teams are left trying to evaluate meaningfully different products using sales-provided materials and curated demonstrations.
A better framework starts with five questions — each mapped to a specific type of evidence that a serious vendor should be able to provide.
| Question to ask | What a credible answer looks like | Red flags |
|---|---|---|
| What is your pass@1 on end-to-end PA workflows? | A specific number on a standardized benchmark, with methodology disclosed | "Our demos speak for themselves" / accuracy scores on clinical Q& A |
| How do your agents perform under consistency testing? | Pass@k scores showing the agent reliably repeats correct results across runs | No consistency data; "our agents are deterministic" (they are not) |
| How do you handle multi-role workflows and handoffs? | Evidence of tested provider-payer handoff scenarios, with failure mode documentation | Only single-role demos; "handoffs are in the roadmap" |
| What is your audit trail architecture? | Append-only session logs, human-readable, reproducible — not framework abstractions | "We log everything" with no specifics on what "everything" means for a denial audit |
| How does your agent handle escalation — and can I verify it? | Documented HITL policies, tested escalation workflows, verifiable routing rules | "The agent knows when to escalate" with no test evidence |
A vendor who cannot answer these questions with evidence — not slides, but data from standardized testing — is telling you something important about the gap between what they have built and what they are selling.
The right question is not "which vendor demo looked most impressive?" It is "which agent, tested on standardized healthcare workflows under consistent conditions, performed best on the specific cases my organization actually processes?"
Deployment Is Not the Finish Line
The most common mistake in healthcare AI governance is treating production deployment as the endpoint of the evaluation process. It is not. It is the beginning of a new evaluation problem — one that is harder, because it involves real patients, real data, and real consequences.
Three things change after an agent is deployed, and each one can silently degrade performance:
- Workflows change. CMS issues new rules. Payers update clinical policy bulletins. A new MHPAEA requirement takes effect. An agent trained on last quarter's policies may apply them incorrectly to this quarter's cases — and the failure will be invisible until a denial audit surfaces it.
- Models change. The frontier model the agent runs on is updated. Model behavior shifts. Prompts that worked reliably on Claude Opus 4.6 may behave differently on Opus 4.7. In a graph-based system, model updates can break workflows outright. In a well-governed harness, every model update should trigger a re-evaluation against production-representative cases before the change goes live.
- Cases change. The distribution of cases an agent handles in production will drift from the distribution it was evaluated on. New member cohorts, new plan configurations, new provider networks — each one introduces variation that the pre-deployment evaluation may not have covered.
Continuous evaluation is not a luxury for healthcare AI. It is a compliance requirement in everything but name. Organizations that deploy agents into prior authorization, utilization management, and care management workflows without a continuous evaluation infrastructure are operating with a governance gap that regulators — and plaintiffs — will eventually find.
The Agent Governance Checklist
Before Pilot
- Run the agent on standardized workflow benchmarks covering your target use cases (PA, UM, CM)
- Test consistency — run the same cases multiple times and verify pass@k scores
- Document all seven failure modes and which ones your evaluation covers
- Define escalation rules and verify them in test conditions before any patient touches the workflow
- Confirm audit trail architecture: every decision must be human-readable and reproducible
Before Production Rollout
- Simulate the full provider-payer handoff — not just the provider-side or payer-side workflow in isolation
- Test against plan-specific and state-specific policy variations, not just generic clinical guidelines
- Define the minimum acceptable pass@1 threshold for each workflow type before deployment, in writing
- Establish the HITL policies that govern which decisions always require human review
- Run a parallel pilot — agent decisions alongside human decisions — and compare error rates before going live
After Deployment (Ongoing)
- Re-evaluate on policy changes — any CMS rule update, plan bulletin revision, or formulary change should trigger a targeted re-test
- Re-evaluate on model updates — any frontier model upgrade should go through a regression suite before agents are switched over
- Monitor denial rates and appeal outcomes — a rising appeal overturn rate is a leading indicator of agent policy interpretation failure
- Run scheduled consistency checks — the same representative cases, at regular intervals, to detect performance drift
- Maintain a versioned failure log — every identified failure mode, its root cause, its fix, and its re-test result
The Infrastructure That Does This at Scale
actAVA KORA is built around exactly this framework. The RED layer — agent testing and remediation — handles pre-production risk, workflow simulation, vendor-configuration comparison, and the failure analysis that surfaces which of the seven failure modes an agent is exhibiting and why. The GREEN layer — continuous learning — handles post-deployment governance: capturing every interaction, running continuous evals, and feeding failure patterns back into agent improvement.
And the χ-Bench benchmark — built with 20+ clinical and academic institutions, open-sourced under Apache 2.0 — provides the standardized, reproducible measurement layer that makes all five governance questions answerable with data rather than demos.
- Readiness: Are our internal or vendor agents safe enough to pilot?
- Simulation: How do they perform on realistic healthcare edge cases?
- Comparison: Which agent, model, or vendor stack performs best on our specific workflows?
- Failure analysis: Where do agents break — reasoning, handoffs, policy interpretation, tool use, documentation, or escalation?
- Governance: Once deployed, how do we keep testing them as workflows, policies, and models change?
The era of "deploy it and see" is ending in healthcare AI. Regulatory deadlines are specific. Adverse event liability is real. The workforce that would catch agent errors is shrinking. And the benchmarks now exist to measure the gap before it becomes a patient safety event.
The organizations that will successfully scale healthcare AI are the ones building evaluation infrastructure now — not as an afterthought, but as the foundation on which deployment sits.
Open benchmark, live leaderboard, Apache 2.0. Test before you deploy at actava.ai/benchmarks

Written by
Weiran Yao
CAIO & Co-Founder